

What is Long Document Classification?
Long document classification is a specialized subfield of document classification within Natural Language Processing (NLP) that focuses on categorizing documents containing 1,000+ words (2+ pages), such as academic papers, legal contracts, and technical reports. Unlike short-text classification, long documents present challenges like input length constraints (e.g., 512 tokens in BERT), loss of contextual coherence when splitting the document, high computational cost, and the need for complex label structures like multi-label or hierarchical classification.
Executive Summary
This benchmark study evaluates various approaches for classifying lengthy documents (7,000-14,000 words ≈ 14-28 pages ≈ short to medium academic papers) across 11 academic categories. XGBoost emerged as the most versatile solution, achieving F1-scores (balanced measure combining precision and recall) of 75-86 with reasonable computational requirements (Chen and Guestrin, 2016). Logistic Regression provides the best efficiency-performance trade-off for resource-constrained environments, training in under 20 seconds with competitive accuracy (Genkin, Lewis and Madigan, 2005). Surprisingly, RoBERTa-base significantly underperformed despite its general reputation, while traditional machine learning approaches proved highly competitive against advanced transformer models (Liu et al., 2019).
Our experiments analyzed 27,000+ documents across four complexity categories from simple keyword matching to large language models, revealing that traditional ML methods often outperform sophisticated transformers while using 10x fewer computational resources. These counter-intuitive results challenge common assumptions about the necessity of complex models for long document classification tasks.
Quick Recommendations
- Best Overall: XGBoost (F1: 86, fast training)
- Most Efficient: Logistic Regression (trains in <20s)
- GPU Available: BERT-base (Devlin et. al, 2019) (F1: 82, but slower)
- Avoid: Keyword-based methods, RoBERTa-base
Study Methodology & Credibility
- Dataset Size: 27,000+ documents across 11 academic categories [Download]
- Hardware Specification: 15x vCPUs, 45GB RAM, NVIDIA Tesla V100S 32GB
- Reproducibility: All code and configurations are available on GitHub
Key Research Findings (Verified Results)
- XGBoost achieved an 86% F1-score on 27,000 academic documents
- Traditional ML methods train 10x faster than transformer models
- BERT requires 2GB+ GPU memory vs 100MB RAM for XGBoost
- RoBERTa-base achieved just a 57% F1-score, falling short of expectations in low-data settings
- Training transformer-based models on the full dataset isn’t justifiable due to the extremely long training time (over 4 hours). Notably, as the data volume grows, model complexity increases and training time rises exponentially
How to Choose the Right Document Classification Method for Long Documents with a Small Number of Samples (~100 to 150 Samples)
| Aspect | Logistic Regression | XGBoost | BERT-base |
|---|---|---|---|
| Best Use Case | Resource-constrained | Production systems | Research applications |
| Training Time | 3 seconds | 35 seconds | 23 minutes |
| Accuracy (F1 %) | 79 | 81 | 82 |
| Memory Requirements | 50MB RAM | 100MB RAM | 2GB GPU RAM |
| Implementation Difficulty | Low | Medium | High |
Table of Contents
- Introduction
- Classification Methods: Simple to Complex
- Technical Specifications
- Results and Analysis
- Deployment Scenarios
- Frequently Asked Questions
- Conclusion
1. Introduction
Long document classification is a specialized subfield of document classification within Natural Language Processing (NLP). At its core, document classification involves assigning one or more predefined categories or labels to a given document based on its content. This is a fundamental task for organizing, managing, and retrieving information efficiently in various domains, from legal and healthcare to news and customer reviews.
In long document classification, the term “long” refers to the substantial length of the documents involved. Unlike short texts—such as tweets, headlines, or single sentences—long documents can span multiple paragraphs, full articles, books, or even legal contracts. This extended length presents unique challenges that traditional text classification methods often struggle to address effectively.
Main Challenges in Long Document Classification
- Contextual Information: Long documents contain much richer and more complex context. Accurately understanding and classifying them requires processing information spread across multiple sentences and paragraphs, not just a few keywords.
- Computational Complexity: Many advanced NLP models, especially Transformer-based ones like BERT, have limits on the maximum input length they can handle efficiently. Their self-attention mechanisms, while powerful for capturing word relationships, become computationally expensive (O(N²) complexity – grows exponentially with document length) and memory-intensive when dealing with very long texts.
- Information Density and Sparsity: Although long documents contain a lot of information, the most important features for classification are often sparsely distributed. This makes it challenging for models to detect and focus on these key signals amidst large amounts of less relevant content.
- Maintaining Coherence: A common approach is to split long documents into smaller chunks. However, this can break the flow and context, making it harder for models to grasp the overall meaning and make accurate classifications.
Study Objectives
In this benchmark study, we evaluate various long document classification methods from a practical and software development standpoint. Our objective is to identify which approach best addresses the unique challenges of long document processing, based on the following criteria:
- Efficiency: Models should be able to process long documents efficiently in terms of time and memory
- Accuracy: Models should be able to accurately classify documents, even with long lengths
- Robustness: Models should be robust to varying document lengths and different types of information organization
2. Classification Methods: Simple to Complex
This section presents four categories of classification methods, ranging from simple keyword matching to sophisticated language models. Each method represents different trade-offs between accuracy, speed, and implementation complexity.
2.1 Simple Methods (No Training Required)
These methods are quick to implement and perform well when the documents are relatively simple and not structurally complex. Typically rule-based, pattern-based, or keyword-based, they require no training time, which makes them especially robust to changes in the number of labels.
When to use: Known document structures, rapid prototyping, or when training data is unavailable.
Main advantage: Zero training time and high interpretability.
Main limitation: Poor performance on complex or nuanced classification tasks.
Keyword-Based Classification
The process begins by extracting a set of representative keywords for each category from the document set. During testing (or prediction), the classification follows these basic steps:
- Tokenize the document
- Count the number of keyword matches for each category
- Assign the document to the category with the highest match count or keyword density
More advanced tools like YAKE (Yet Another Keyword Extractor) can be used to automate keyword extraction (Campos et al., 2020). Additionally, if category names are known in advance, external keywords—those not found within the documents—can be added to the keyword sets with the help of intelligent models.
Keyword-Based Classification Diagram

TF-IDF (Term Frequency-Inverse Document Frequency) + Similarity
While it uses TF-IDF vectors, it doesn’t require training a machine learning model. Instead, you select a few representative documents for each category—often just 2 or 3 examples per category are sufficient—and compute their TF-IDF vectors, which reflect the importance of each word within the document relative to the rest of the corpus.
Next, for each category, you calculate a mean TF-IDF vector to represent a typical document in that class. During testing, you convert the new document into a TF-IDF vector and compute its cosine similarity with each category’s mean vector. The category with the highest similarity score is selected as the predicted label.
This approach is particularly effective for long documents, as it takes into account the entire content rather than focusing on a limited set of keywords. It is also more robust than basic keyword matching and still avoids the need for supervised training.
TF-IDF-Based Classification Diagram

Next steps: If simple methods meet your accuracy requirements, proceed with keyword extraction using YAKE or manual selection. Otherwise, consider intermediate methods for better performance.
Key Takeaway: Simple methods offer rapid implementation and zero training time but suffer from poor accuracy on complex classification tasks. Best suited for well-structured documents with clear keyword patterns.
2.2 Intermediate Methods (Traditional ML)
Having covered simple methods, we now examine intermediate approaches that require training but offer significantly better performance.
When to use: When you have labeled training data and need reliable, fast classification.
Main advantage: Excellent balance of accuracy, speed, and resource requirements.
Main limitation: Requires feature engineering and training data.
One of the most accessible and time-tested approaches for document classification — especially as a baseline — is the combination of TF-IDF vectorization with traditional machine learning classifiers such as Logistic Regression, Support Vector Machines (SVMs), or XGBoost. Despite its simplicity, this method continues to be a competitive option for many real-world applications, especially when interpretability, speed, and ease of deployment are prioritized.
Method Overview
The technique is straightforward: the document text is converted into a numerical representation using TF-IDF, which captures how important a word is relative to a corpus. This produces a sparse vector of weighted word counts.
The resulting vector is then passed into a classical classifier, typically:
- Logistic Regression for linear separability and fast training
- SVM for more complex boundaries
- XGBoost for high-performance, tree-based modeling
The model learns to associate word presence and frequency patterns with the desired output labels (e.g., topic categories or document types).
Handling Long Documents
By default, TF-IDF can process the entire document at once, making it suitable for long texts without the need for complex chunking or truncation. However, if documents are extremely lengthy (e.g., exceeding 5,000–10,000 words), it may be beneficial to:
- Chunk the document into smaller segments (e.g., 1,000–2,000 words)
- Classify each chunk individually
- And then aggregate results using majority voting or average confidence scores
This chunking strategy can improve stability and mitigate sparse vector issues while still remaining computationally efficient.
ML-Based Classification Diagram

Next steps: Start with Logistic Regression for baseline performance, then try XGBoost for optimal accuracy. Use 5-fold cross-validation with stratified sampling for robust evaluation.
Key Takeaway: Intermediate methods demonstrate the best balance of accuracy and efficiency. XGBoost consistently delivers top performance while Logistic Regression excels in resource-constrained environments.
2.3 Complex Methods (Transformer-Based)
Moving beyond traditional approaches, we explore transformer-based methods that leverage pre-trained language understanding.
When to use: When maximum accuracy is needed and GPU resources are available.
Main advantage: Deep language understanding and high accuracy potential.
Main limitation: Computational intensity and 512-token limit requiring chunking.
For many classification tasks involving moderately long documents — typically in the range of 300 to 1,500 words — fine-tuned transformer models like BERT, DistilBERT (Sanh et al., 2019), and RoBERTa represent a highly effective and accessible middle-ground solution. These models strike a balance between traditional machine learning approaches and large-scale models like Longformer or GPT-4.
Architecture and Training
At their core, these models are pretrained language models that have learned general linguistic patterns from large corpora such as Wikipedia and BookCorpus. When fine-tuned for document classification, the architecture is extended by adding a simple classification head — usually a dense layer — on top of the transformer’s pooled output.
Fine-tuning involves training this extended model on a labeled dataset for a specific task, such as classifying reports into categories like Finance, Sustainability, or Legal. During training, the model adjusts both the classification head and (optionally) the internal transformer weights based on task-specific examples.
Handling Length Limitations
One key limitation of standard transformers like BERT and DistilBERT is that they only support sequences up to 512 tokens. For long documents, this constraint must be addressed by:
- Truncation: Simply cutting off the text after the first 512 tokens. Fast, but may ignore critical information later in the document.
- Chunking: Splitting the document into overlapping or sequential segments, classifying each chunk individually, and then aggregating predictions using majority vote, average confidence, or attention-based weighting.
- Preprocessing and data preparation: In this approach, long documents are first broken down into shorter texts (up to 512 tokens) using preprocessing techniques like keyword extraction or summarization. While these methods may sacrifice some coherence between segments, they offer faster training and classification times.
While chunking adds complexity, it enables these models to handle documents up to several thousand words while maintaining reasonable performance.
Transformer-Based Classification Diagram

Next steps: Begin with DistilBERT for faster training, then upgrade to BERT if accuracy gains justify the computational cost. Implement overlapping chunking strategies for documents exceeding 512 tokens.
Key Takeaway: Transformer methods offer high accuracy but require significant computational resources. BERT-base performs well while RoBERTa-base surprisingly underperforms, highlighting the importance of empirical evaluation over reputation.
2.4 Most Complex Methods (Large Language Models)
Finally, we examine the most sophisticated approaches using large language models for instruction-based classification.
When to use: Zero-shot classification, extremely long documents, or when training data is limited.
Main advantage: No training required, handles very long contexts, high accuracy.
Main limitation: High API costs, slower inference, and requires internet connectivity.
These methods are powerful models that are able to understand complex documents with minimal or no training. They are suitable for tasks such as instruction-based or zero-shot classification.
API-Based Classification
OpenAI GPT-4 / Claude / Gemini 1.5: This approach leverages the instruction-following capability of models like GPT-4, Claude, and Gemini through API calls. These models can handle long-context inputs—up to 128,000 tokens in some cases (which is roughly equivalent to 300+ pages of text ≈ multiple academic papers).
The method is simple in concept: you provide the model with the document text (or a substantial chunk of it) along with a prompt like:
“You are a document classification assistant. Given the text below, classify the document into one of the following categories: [Finance, Legal, Sustainability].”
Once prompted, the LLM analyzes the document in real time and returns a label or even a confidence score, often with an explanation.
LLM-Based Classification Diagram

RAG-Enhanced Classification
LLMs Combined with RAG (Retrieval-Augmented Generation): Retrieval-Augmented Generation (RAG) is a more advanced architectural pattern that combines a vector-based retrieval system with an LLM. Here’s how it works in a classification setting:
- First, the long document is split into smaller, semantically meaningful chunks (e.g., by section, heading, or paragraph)
- Each chunk is embedded into a dense vector using an embedding model (like OpenAI’s text-embedding or SentenceTransformers)
- These vectors are stored in a vector database (like FAISS or Pinecone)
- When classification is needed, the system retrieves only the most relevant document chunks and passes them to an LLM (like GPT-4) along with a classification instruction
LLM-Based + RAG Classification Diagram
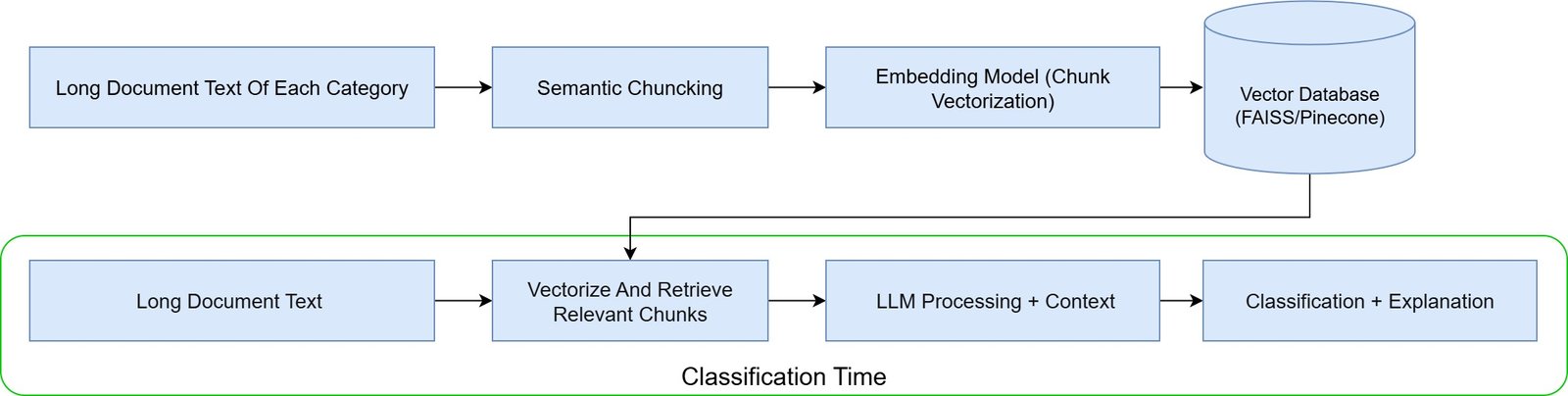
This method allows you to process long documents efficiently and scalably, while still benefiting from the power of large models.
Next steps: Start with simpler prompting strategies before implementing RAG. Consider cost-effectiveness compared to fine-tuned models for your specific use case.
Key Takeaway: LLM methods provide powerful zero-shot capabilities for long documents but come with high API costs and latency. Best suited for scenarios where training data is limited or extremely long context processing is required.
2.5 Model Comparison Summary
The following table provides a comprehensive overview of all classification methods, comparing their capabilities, resource requirements, and optimal use cases to help guide your selection process.
| Methods | Model/Class | Max Tokens | Chunking Needed? | Ease of Use (1-5) | Accuracy (1-5) | Resource Usage | Best For |
|---|---|---|---|---|---|---|---|
| Simple | Keyword/Regex Rules | ∞ | No | 1 (Easy) | 2 (Low) | Minimal CPU & RAM | Known structure/formats (e.g., legal) |
| TF-IDF + Similarity | ∞ | No | 2 | 2-3 | Low CPU, ~150MB RAM | Labeling based on few samples | |
| Intermediate | TF-IDF + ML | ∞ (entire doc) | Optional | 1 (Easy) | 3 (Good) | Low CPU, ~100MB RAM | Fast baselines, prototyping |
| Complex | BERT / DistilBERT / RoBERTa | 512 tokens | Yes | 3 | 4 (High) | Needs GPU / ~1–2GB RAM | Short/medium texts, fine-tuning possible |
| Longformer / BigBird | 4,096–16,000 | No | 4 | 5 (Highest) | GPU (8GB+), ~3–8GB RAM | Long reports, deep accuracy needed | |
| Most Complex | GPT-4 / Claude / Gemini | 32k–128k tokens | No or Light | 4 (API-based) | 5 (Highest) | High cost, API limits | Zero-shot classification of big docs |
Key Insight: Traditional ML (XGBoost) often outperforms advanced transformers while using 10x fewer resources.
2.6 Referenced Datasets & Standards
The following datasets provide excellent benchmarks for testing long document classification methods:
| Dataset | Avg Length | Domain | Page Length | Categories | Source |
|---|---|---|---|---|---|
| S2ORC | 3k–10k tokens | Academic | 6–20 | Dozens | Semantic Scholar |
| ArXiv | 4k–14k words | Academic | 8–28 | 38+ | arXiv.org |
| BillSum | 1.5k–6k tokens | Government | 3–12 | Policy categories | FiscalNote |
| GOVREPORT | 4k–10k tokens | Gov/Finance | 8–20 | Various | Government Agencies |
| CUAD | 3k–10k tokens | Legal | 6–20 | Contract clauses | Atticus Project |
| MIMIC-III | 2k–5k tokens | Medical | 3–10 | Clinical notes | PhysioNet |
| SEC 10-K/Q | 10k–50k words | Finance | 20–100 | Company/section | SEC EDGAR |
Context: All datasets are publicly available with proper licensing agreements. Training times vary from 2 hours (small datasets) to 2 days (large datasets) on standard hardware.
3. Technical Specifications
3.1 Evaluation Criteria
Accuracy Assessment: Using accuracy, precision (true positives / predicted positives), recall (true positives / actual positives), and F1-score (harmonic mean of precision and recall) criteria.
Resource and Time Assessment: The amount of time and resources used during training and testing.
3.2 Experiment Settings
Hardware Configuration: 15x vCPUs, 45GB RAM, NVIDIA Tesla V100S 32GB.
Evaluation Methodology: 5-fold cross-validation with stratified sampling was used to ensure robust statistical evaluation.
Software Libraries: scikit-learn 1.3.0, transformers 4.38.0, PyTorch 2.7.1, XGBoost 3.0.2
3.2.1 Dataset Selection
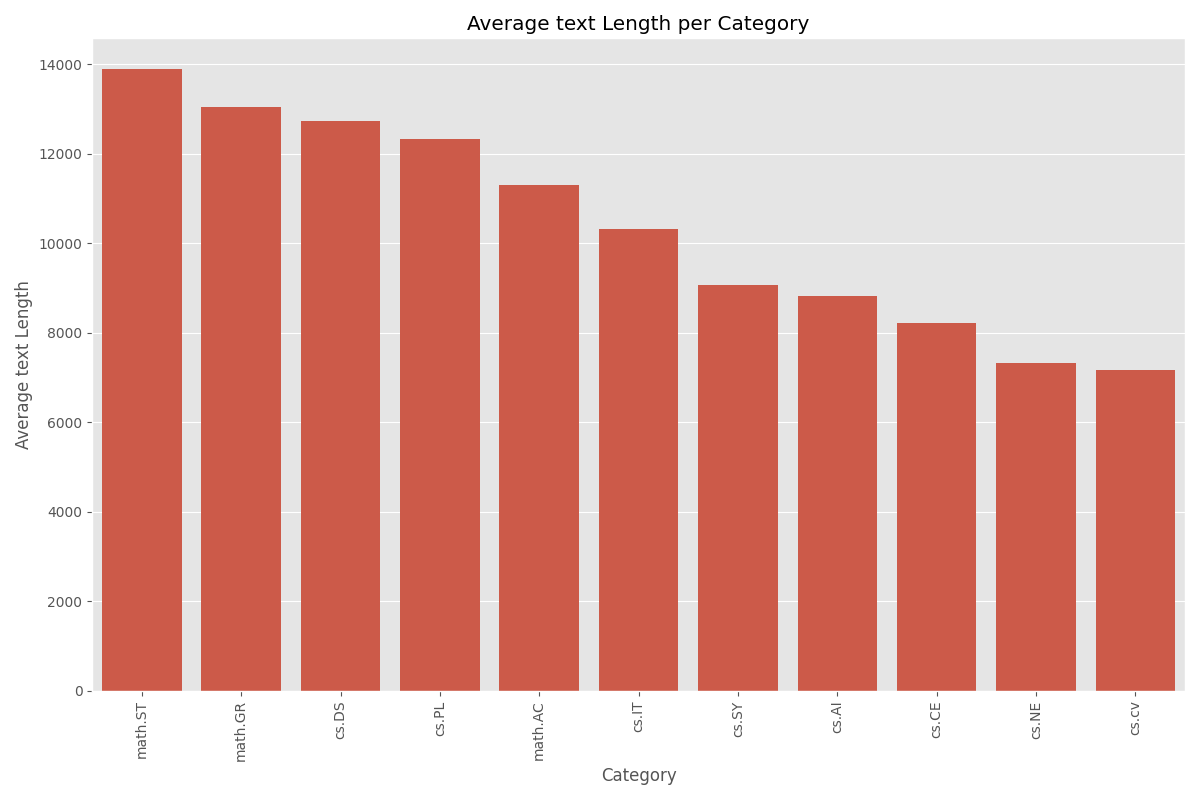
We use the ArXiv Dataset with 11 labels that have the largest length variation across academic domains.
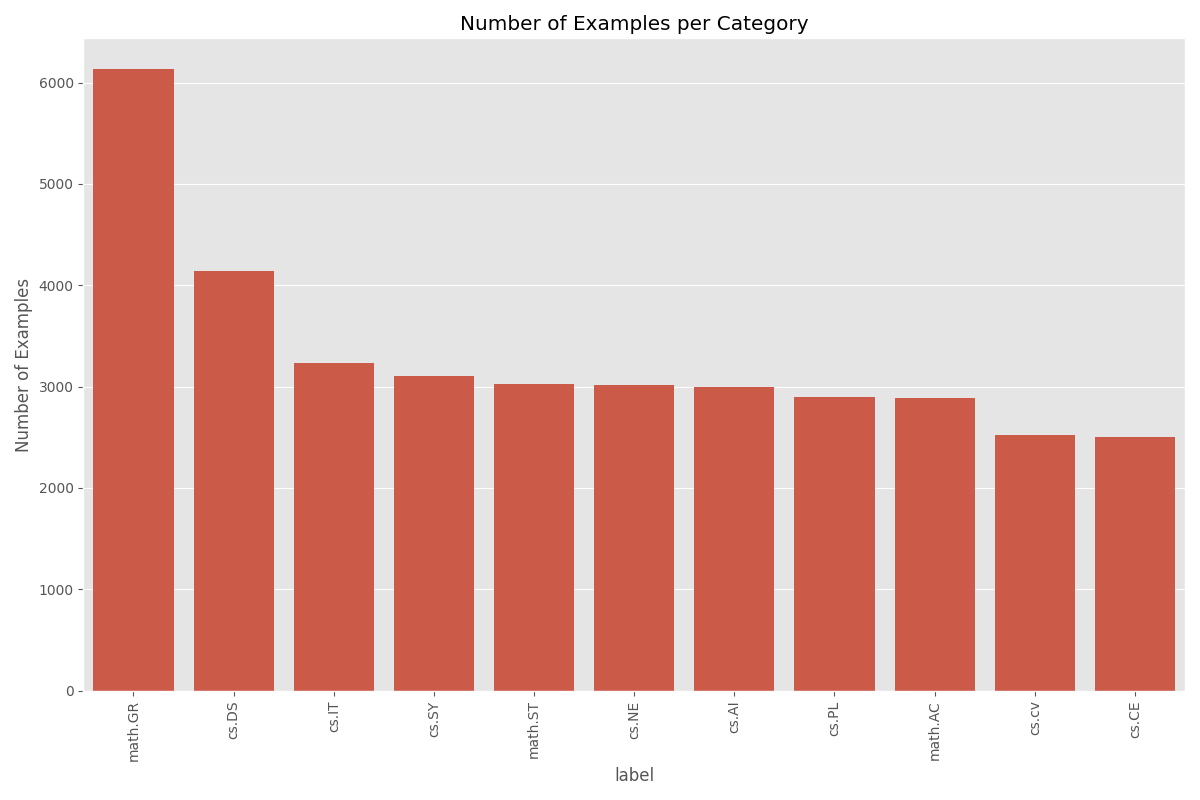
Document Length Context: To better contextualize these word counts, we can convert them to number of pages, using the standard estimate of 500 words per page for double-spaced academic text (14,000 words ≈ 28 pages ≈ short academic paper). By this measure:
- math.ST averages around 28 pages
- math.GR and cs.DS are about 25–26 pages
- cs.IT and math.AC average roughly 20–24 pages
- while cs.CV and cs.NE average only 14–15 pages
This significant variation demonstrates differences in writing styles, document depth, or research reporting norms across fields. Fields like mathematics and theoretical computer science tend to produce more comprehensive or technically dense documents, whereas applied areas like computer vision may favor more concise communication.
3.2.2 Data Size and Training/Test Division
Expected training time on standard hardware: 30 minutes to 8 hours, depending on method complexity.
Minimum Training Data Requirements:
- Simple methods: 50+ samples per class
- Logistic Regression: 100+ samples per class
- XGBoost: 1,000+ samples for optimal performance
- BERT/Transformer models: 2,000+ samples per class
In all experiments, 30% of the data was reserved as the test set. To evaluate the robustness of the model, several variations of the dataset were used: the original class-distributed data, a balanced dataset based on the minimum class size (~2,505 samples), and additional balanced datasets with fixed sizes of 100, 140, and 1,000 samples per class.
4. Results and Analysis
Our experiments reveal counter-intuitive results about the performance-efficiency trade-offs in long document classification.
Why Traditional ML Outperforms Transformers
Our benchmark demonstrates that traditional machine learning approaches offer several advantages:
- Computational Efficiency: Process entire documents without token limits
- Training Speed: 10x faster training times with comparable accuracy
- Resource Requirements: Function effectively on standard CPU hardware
- Scalability: Handle large document collections without GPU infrastructure
4.1 Performance Rankings
The comparative evaluation across four datasets—Original, Balanced-2505, Balanced-140, and Balanced-100—demonstrates clear performance hierarchies:
Top Performers by F1-Score:
XGBoost achieved the highest F1-scores on three datasets:
- Original: F1 = 86
- Balanced-2505: F1 = 85
- Balanced-100: F1 = 75
BERT-base was the top performer on the Balanced-140 dataset:
- Balanced-140: F1 = 82 (vs. XGBoost: 81)
Logistic Regression and SVM also delivered competitive results:
- F1 range: 71–83
DistilBERT-base maintained decent performance across settings:
- F1 ≈ 75–77
RoBERTa-base consistently underperformed:
- F1 as low as 57, especially in low-data settings
Keyword-based methods had the lowest F1-scores (53–62)
Key Takeaway: Although XGBoost generally performs best across most dataset scenarios, BERT-base slightly outperforms it in mid-sized datasets such as Balanced-140. This suggests that transformer models can surpass traditional machine learning methods when a moderate amount of data and sufficient GPU resources are available. However, the performance gap is not significant, and XGBoost remains the most well-rounded option, offering high accuracy, robustness, and computational efficiency across different dataset sizes.
4.2 Cost-Benefit Analysis of Each Method
An in-depth analysis of training and inference times reveals a wide gap in resource requirements between traditional ML methods and transformer-based models:
Training and Inference Times:
Most Efficient
- Logistic Regression:
- Training: 2–19 seconds across datasets
- Inference: ~0.01–0.06 seconds
- Resource Use: Minimal CPU & RAM (~50MB)
- Best suited for rapid deployment and resource-constrained environments.
- XGBoost:
- Training: Ranges from 23s (Balanced-100) to 369s (Balanced-2505)
- Inference: ~0.00–0.09 seconds
- Resource Use: Efficient on CPU (~100MB RAM)
- Excellent trade-off between speed and accuracy, particularly for large datasets.
Resource Intensive
- SVM:
- Training: Up to 2,480s
- Inference: As high as 1,322s
- High complexity and runtime make it unsuitable for real-time or production use.
- Transformer Models:
- DistilBERT-base: Training ≈ 900–1,400s; Inference ≈ 140s
- BERT-base: Training ≈ 1,300–2,700s; Inference ≈ 127–138s
- RoBERTa-base: Worst performance and highest training time (up to 2,718s)
- GPU-intensive (≥2GB RAM) and slow inference make them impractical unless maximum accuracy is critical.
Inefficient in Inference
- Keyword-based Methods:
- Training: Very fast (as low as 3–135s)
- Inference: Surprisingly slow — up to 335s
- Although easy to implement, the slow inference and poor accuracy make them unsuitable for large-scale or real-time use.
Key Takeaway: Traditional ML methods such as Logistic Regression and XGBoost offer the best cost-efficiency for real-world deployment, providing fast training, near-instant inference, and high accuracy without relying on GPUs. Transformer models provide improved performance only on certain datasets (e.g., BERT on Balanced-140) but incur significant resource and time costs, which may not be justified in many scenarios. It’s important to note that the resource requirements of transformer models increase exponentially with growing complexity, such as larger data volumes.
4.3 Complete Model Evaluation Summary
| Dataset | Methods | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Train Time (s) | Test Time (s) |
|---|---|---|---|---|---|---|---|---|
| Original | Simple | Keyword-Based | 56 | 57 | 56 | 55 | 135 | 335 |
| Intermediate | Logistic Regression | 84 | 83 | 84 | 83 | 19 | 0.06 | |
| SVM | 84 | 83 | 84 | 83 | 2480 | 1322 | ||
| MLP | 80 | 80 | 80 | 80 | 426 | 0.53 | ||
| XGBoost | 86 | 86 | 86 | 86 | 364 | 0.08 | ||
| Balanced-2505 | Simple | Keyword-Based | 53 | 53 | 53 | 53 | 50 | 253 |
| Intermediate | Logistic Regression | 83 | 83 | 83 | 83 | 17 | 0.05 | |
| SVM | 82 | 82 | 82 | 82 | 1681 | 839 | ||
| MLP | 78 | 79 | 78 | 78 | 301 | 0.41 | ||
| XGBoost | 85 | 85 | 85 | 85 | 369 | 0.09 | ||
| Balanced-100 | Simple | Keyword-Based | 54 | 56 | 54 | 54 | 3 | 10 |
| Intermediate | Logistic Regression | 72 | 71 | 72 | 71 | 2 | 0.01 | |
| SVM | 72 | 73 | 72 | 72 | 7 | 2 | ||
| MLP | 73 | 73 | 73 | 73 | 15 | 0.02 | ||
| XGBoost | 76 | 76 | 76 | 75 | 23 | 0 | ||
| Complex | DistilBERT-base | 75 | 75 | 75 | 75 | 907 | 141 | |
| BERT-base | 77 | 78 | 77 | 77 | 1357 | 127 | ||
| RoBERTa-base | 55 | 62 | 55 | 57 | 1402 | 124 | ||
| Balanced-140 | Simple | Keyword-Based | 62 | 63 | 62 | 62 | 3 | 14 |
| Intermediate | Logistic Regression | 79 | 79 | 79 | 79 | 3 | 0.01 | |
| SVM | 78 | 79 | 78 | 78 | 14 | 4 | ||
| MLP | 78 | 79 | 78 | 78 | 19 | 0.02 | ||
| XGBoost | 81 | 80 | 81 | 80 | 34 | 0 | ||
| Complex | DistilBERT-base | 77 | 77 | 77 | 77 | 1399 | 142 | |
| BERT-base | 82 | 82 | 82 | 82 | 2685 | 138 | ||
| RoBERTa-base | 64 | 64 | 64 | 64 | 2718 | 139 |
4.4 Model Selection Decision Matrix
| Criteria | Best Model | Notes |
|---|---|---|
| Highest Accuracy (All Data) | XGBoost | F1 = 86 |
| Highest Accuracy (Small-Mid Data) – CPU access | XGBoost | F1 = 81 |
| Highest Accuracy (Small-Mid Data) – GPU access (All Data) | BERT-base | F1 = 82 |
| Fastest Model | Logistic Regression | Training in <20s |
| Best Efficiency (Speed/Accuracy Trade-off) | Logistic Regression | Excellent balance between runtime, simplicity, and accuracy |
| Best Large-Scale Classifier | XGBoost | Scales well to large datasets, robust to imbalance |
| Best GPU Utilization | BERT-base | High accuracy when GPU is available; better than RoBERTa/DistilBERT-base |
| Not Recommended | RoBERTa-base, Keyword-Based | Poor accuracy, long inference times, no performance edge |
4.5 Robustness Analysis
This section analyzes the robustness of different models across various dataset sizes and conditions, highlighting their strengths, limitations, and areas needing further investigation.
High Confidence Findings:
- XGBoost demonstrates robust performance across varying dataset sizes, especially for large and small data regimes (Original, Balanced-100).
- BERT-base shows strong performance in mid-sized datasets (Balanced-140), indicating that transformer models can outperform traditional ML under the right data and compute conditions.
- Logistic Regression remains a consistently reliable baseline, delivering strong results with minimal computational cost.
- Traditional ML models, particularly XGBoost and Logistic Regression, offer high efficiency with competitive accuracy, especially when computational resources are limited.
Areas Requiring Further Research:
- RoBERTa-base’s underperformance across all settings is unexpected and may stem from task-specific limitations or suboptimal fine-tuning strategies.
- Transformer chunking strategies require further domain adaptation — current performance may be limited by generic slicing or truncation techniques.
Key Takeaway: While traditional ML methods like XGBoost and Logistic Regression are robust, transformer models such as BERT-base can outperform them under specific conditions. These results underscore the importance of matching model complexity to the data scale and deployment constraints, rather than assuming more sophisticated architectures will yield better results by default.
5. Deployment Scenarios
In this section, we explore deployment scenarios for text classification models, highlighting the best-suited algorithms for different operational constraints—ranging from production systems to rapid prototyping—based on trade-offs between accuracy, efficiency, and resource availability.
Production Systems
- Recommended: XGBoost
- Why: Achieves the highest F1-score (86) on full datasets with fast inference (~0.08s) and moderate training time (~6 minutes).
- Use Case: High-volume or batch processing pipelines where both accuracy and throughput matter.
- Notes: Robust across dataset sizes; suitable for environments with standard CPU infrastructure.
Resource-Constrained Environments
- Recommended: Logistic Regression
- Why: Extremely lightweight (training <20s, inference ~0.01s), with competitive F1-scores (up to 83).
- Use Case: Edge devices, embedded systems, and low-budget deployments.
- Notes: Also ideal for rapid explainability and debugging.
Maximum Accuracy with GPU Access
- Recommended: BERT-base
- Why: Outperforms XGBoost on moderately sized datasets (F1 = 82 vs. 80 on Balanced-140).
- Use Case: Research, compliance/legal document classification, and applications where marginal accuracy improvements are mission-critical.
- Notes: Requires GPU infrastructure (~2GB RAM); longer training and inference times.
Rapid Prototyping
- Recommended Pipeline: Logistic Regression → XGBoost → BERT-base
- Why: Enables iterative refinement — start simple and scale complexity only if needed.
- Use Case: Early-stage experimentation, category testing, or resource-phased projects.
Not Recommended
- RoBERTa-base: Poor F1-scores (as low as 57), long training/inference time, no performance edge.
- Keyword-Based Methods: Fast to implement but low accuracy (F1 ≈ 53–62) and surprisingly slow inference.
Key Takeaway: The best model for deployment depends on data size, infrastructure constraints, and accuracy needs. XGBoost is optimal for general production, Logistic Regression excels under limited resources, and BERT-base is preferred when accuracy is paramount and GPU compute is available. Defaulting to complexity is discouraged — empirical evidence supports traditional ML for many real-world use cases.
6. Frequently Asked Questions
What is the best method for long document classification?
It depends on your data size and deployment environment:
- XGBoost delivers the highest accuracy overall (F1 = 86 on full dataset) and is the best general-purpose choice.
- BERT-base outperforms other models on mid-sized datasets (F1 = 82 on Balanced-140) when GPU infrastructure is available.
- Logistic Regression is ideal for resource-constrained environments, offering fast training and strong performance with minimal compute.
How does BERT compare to traditional machine learning for document classification?
BERT-base offers higher accuracy on moderately-sized datasets (like Balanced-140), but requires 10–50× more computational resources than traditional models.
- BERT: F1 up to 82, but needs GPUs and longer training time (~45 minutes).
- XGBoost: Similar or better performance on larger or smaller datasets with much faster runtime and CPU-only operation.
Use BERT when maximum accuracy is required and you have GPU capacity. Use traditional ML for speed, simplicity, and cost-efficiency.
What document length is considered “long” in NLP?
Any document over 1,000 words (≈2+ pages) is considered “long.” Many benchmark datasets include documents ranging from 7,000 to 14,000 words (≈14–28 pages).
Long documents pose special challenges:
- Token length limitations (e.g., BERT: 512 tokens)
- Computational cost
- Maintaining contextual coherence over multiple pages
How much training data do you need for document classification?
Minimum requirements: 100 samples per class for basic models, 1,000+ for optimal XGBoost performance, 2,000+ for transformer models.
Can you classify documents in real-time?
Yes — with Logistic Regression and XGBoost, which offer sub-second inference times even on large documents.
- XGBoost: Inference ≈ 0.08s
- Logistic Regression: Inference ≈ 0.01s
- BERT-base: Inference ≈ 2–3 minutes (not suitable for real-time unless optimized)
What’s the accuracy difference between simple and complex methods?
- Simple methods (e.g., keyword-based): F1 ≈ 53–62
- Traditional ML (e.g., XGBoost, Logistic Regression): F1 ≈ 71–86
- Transformer-based (e.g., BERT, DistilBERT): F1 ≈ 75–82
Performance gaps are narrower than expected. Complex models do not always outperform simpler ones, especially in real-world scenarios with limited resources.
When should I choose BERT over XGBoost or Logistic Regression?
Choose BERT-base when:
- You have access to GPU hardware (≥2GB VRAM)
- Your dataset is moderately sized (e.g., 100–1,000 samples/class)
- You need maximum accuracy, such as for legal, compliance, or critical academic categorization
- You’re working in a research setting where computational cost is acceptable
Avoid BERT if:
- You lack GPU resources
- You require real-time classification
- You’re building resource-constrained applications (mobile, embedded, edge)
In those cases, XGBoost or Logistic Regression is more practical.
Why does RoBERTa-base perform poorly despite its strong reputation?
RoBERTa-base surprisingly underperformed in this benchmark (F1 ≈ 57–64), likely due to:
- Poor generalization to long-document chunking without specialized preprocessing
- Lack of task-specific fine-tuning or inadequate learning under low-resource conditions
- Sensitivity to document structure or sequence distribution in academic corpora
This result highlights the need for empirical validation — model reputation doesn’t guarantee performance in all domains. RoBERTa may still perform well with custom fine-tuning, but in this study, it was neither efficient nor accurate.
7. Conclusion
This benchmark study presents a comprehensive evaluation of traditional and modern approaches for long document classification across a range of dataset sizes and resource constraints. Contrary to common assumptions, our findings reveal that complex transformer models do not always outperform simpler machine learning methods, particularly in real-world deployment conditions.
Key Findings Summary
- XGBoost stands out as the most robust and scalable solution overall, achieving the highest F1 score (86) on full-size datasets and demonstrating consistent performance across varying sample sizes. It offers excellent computational efficiency, making it well-suited for production environments that handle large document collections. Nonetheless, it also performs acceptably on smaller datasets—for instance, achieving an F1 score of 81 on Balanced-140.
- BERT-base delivers the highest accuracy on mid-sized datasets (e.g., F1 = 82 on Balanced-140), outperforming XGBoost in that setting. However, it requires GPU infrastructure and incurs significant training and inference time, making it ideal for research or high-stakes applications where resource availability is not a limiting factor.
- Logistic Regression remains an outstanding choice for resource-constrained environments. It trains in under 20 seconds, infers almost instantly, and achieves competitive F1-scores (up to 83), making it ideal for rapid prototyping, embedded systems, and edge deployment.
- RoBERTa-base consistently underperformed, despite its reputation, with F1-scores as low as 57. This underscores the need for empirical benchmarking rather than relying solely on perceived model strength.
- Keyword-based and similarity-based methods are inadequate for complex, multi-class long document classification, despite their simplicity and fast setup. Their low accuracy and unexpectedly long inference times make them unsuitable for serious deployment.
Strategic Recommendations
- Start with traditional ML models like Logistic Regression or XGBoost. They offer strong performance with minimal overhead and allow for fast iteration.
- Use BERT-base only when marginal accuracy improvements are mission-critical and GPU resources are available.
- Avoid overcomplicating early stages of model selection — the results show that simple models often deliver surprisingly competitive results for long-text classification.
- Carefully match your model to your specific deployment scenario, considering the balance between accuracy, runtime, memory requirements, and data availability.
Future Research Directions
Several areas merit deeper investigation:
- Domain-adaptive fine-tuning and chunking strategies for transformer models
- Exploration of hybrid pipelines that combine fast traditional ML backbones with transformer-based reranking or refinement
- Investigation into why RoBERTa underperforms and whether task-specific adaptations could recover its potential
- Evaluation of new long-context transformers (e.g., Longformer, BigBird) on this benchmark
Final Takeaway
This benchmark challenges the belief that model complexity is always justified. In reality, traditional ML models can deliver excellent performance for long document classification — often matching or surpassing transformers in both accuracy and speed, with 10× less computational cost.
The key to success lies not in chasing the most powerful model, but in choosing the right model for your specific data, constraints, and goals.
References
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A., Nunes, C. and Jatowt, A. (2020) ‘YAKE! Keyword Extraction from Single Documents Using Multiple Local Features’, Information Sciences, 509, pp. 257-289.
Chen, T. and Guestrin, C. (2016) ‘XGBoost: A scalable tree boosting system’, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, pp. 785-794.
Devlin, J., Chang, M.W., Lee, K. and Toutanova, K. (2019) ‘BERT: Pre-training of deep bidirectional transformers for language understanding’, in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis: Association for Computational Linguistics, pp. 4171-4186.
Genkin, A., Lewis, D.D. and Madigan, D. (2005) Sparse logistic regression for text categorization. DIMACS Working Group on Monitoring Message Streams Project Report. New Brunswick: Rutgers University.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. and Stoyanov, V. (2019) ‘RoBERTa: A robustly optimized BERT pretraining approach’, arXiv preprint arXiv:1907.11692 [Preprint]. Available at: https://arxiv.org/abs/1907.11692.
Sanh, V., Debut, L., Chaumond, J. and Wolf, T. (2019) ‘DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter’, arXiv preprint arXiv:1910.01108 [Preprint]. Available at: https://arxiv.org/abs/1910.01108.
Download Resources and Libraries
- Liqun W. (2021). Long Document Dataset – GitHub Repository
- S2ORC (Semantic Scholar Open Research Corpus)
- Congressional and California state bills – GitHub Repository
- GOVREPORT – long document summarization dataset
- CUAD (Contract Understanding Atticus Dataset)
- MIMIC-III (Medical Information Mart for Intensive Care)
- SEC 10 K/Q Filings
- scikit-learn 1.3.0
- transformers 4.38.0
- torch 2.7.1
- xgboost 3.0.2
- All code and configurations related to the long document classification Benchmark 2025 – GitHub Repository





