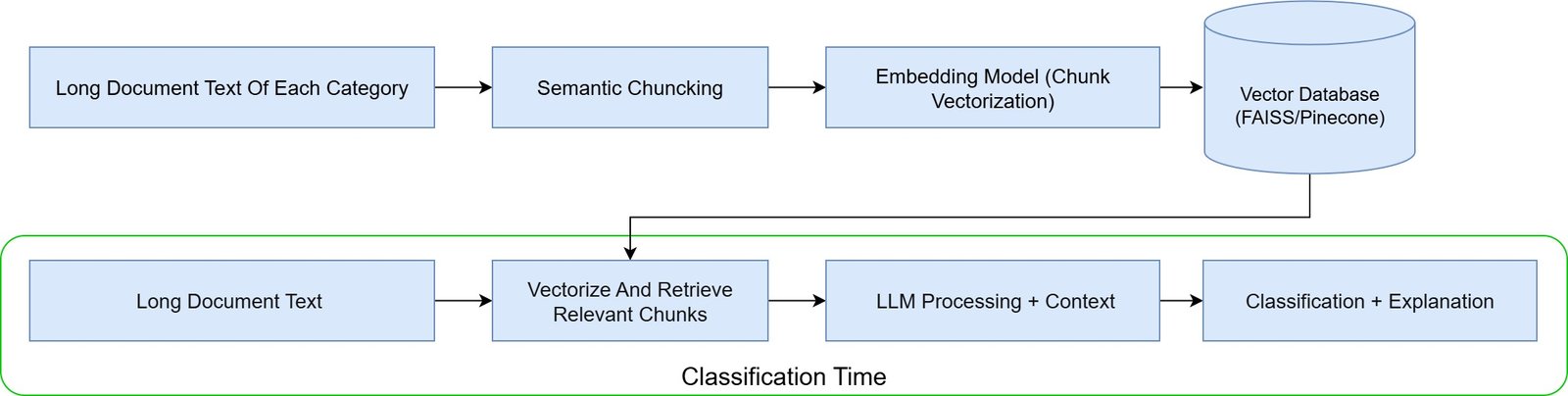
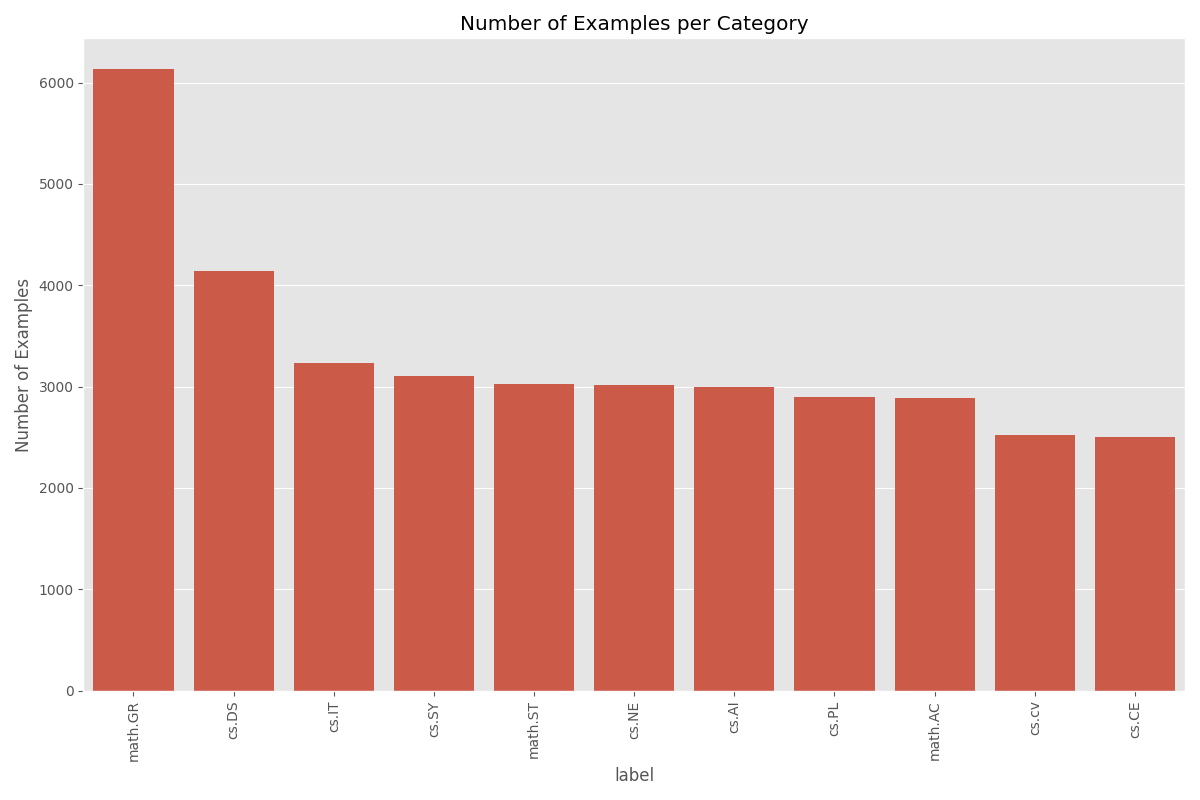
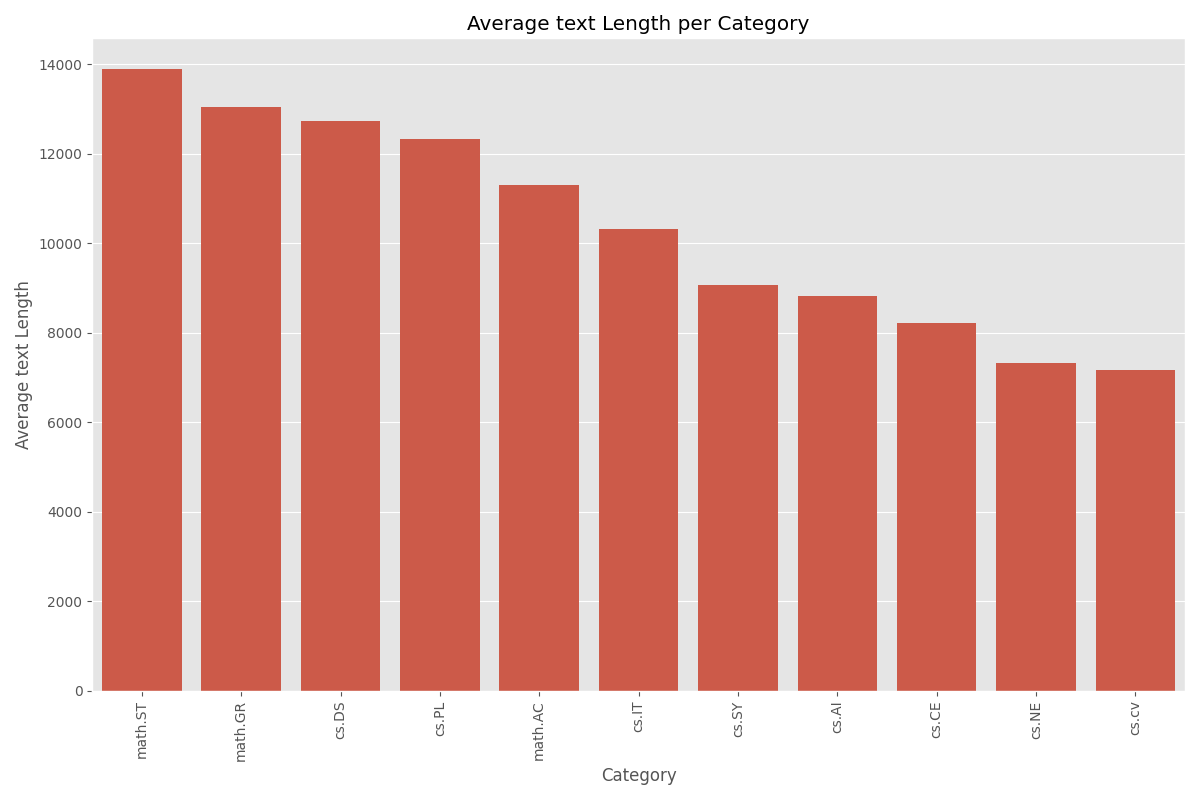
Looking for the best workflow orchestration platform in 2025? This comprehensive comparison of Kestra vs Temporal vs Prefect reveals which workflow orchestrator excels for ETL pipelines, mission-critical systems, and ML workflows based on real production experience. We’ll show you exactly when to use each platform, with code examples and architectural deep-dives.
Table of Contents
- Executive Summary
- Kestra vs Temporal vs Prefect: Core Differences
- Architecture Under the Hood: How These Orchestrators Work
- Show Me the Code: Workflow Definitions in Practice
- How Do These Platforms Handle Data?
- Extensibility Models: Building on Giants
- Performance & Scalability: Workflow Orchestration Benchmarks
- Which Workflow Orchestrator Is Best?
- Real-World Scenarios: Where Each Platform Shines
- The Future of Workflow Orchestration in 2025
- The Bottom Line
At a Glance: Workflow Orchestrator Comparison
Kestra: YAML-based, best for ETL and data pipelines
Temporal: Code-based, best for mission-critical reliability
Prefect: Python-native, best for ML and data science workflows
Executive Summary
In 2018, choosing a workflow orchestrator meant picking between Luigi and Airflow. Simple times. Today? Over 10 active projects compete for your attention, each claiming to be the solution to all your problems.¹ Spoiler alert: they’re not. While Apache Airflow, Dagster, and Luigi remain popular, we focused on these three modern alternatives to Airflow that represent distinct architectural philosophies.
We recently built an Agentic AI Knowledge-Extraction platform using workflow orchestration tools and had to make this choice ourselves. After evaluating orchestration platforms for our high-performance RAG pipeline—which demanded speed, accuracy, and flexibility—we learned that the real differences between modern orchestrators aren’t in their feature lists. They’re in their fundamental architectural philosophies. And these philosophies will either enable or cripple your team.
This workflow orchestration comparison guide dissects three leading workflow automation platforms—Kestra, Temporal, and Prefect—based on our hands-on experience and architectural analysis. I’ll tell you where each one shines, where they frustrate, and most importantly, which one you should choose for your specific needs.
The Three Philosophies: Comparing Workflow Orchestration Tools
Let me be blunt: choosing an orchestrator isn’t about features. It’s about philosophy. And if you pick the wrong philosophy for your team, you’re in for months of pain.
Kestra: The Declarative Data Highway
Kestra brings Infrastructure as Code to workflow automation through YAML workflows, making it a strong Apache Airflow alternative.² Think Kafka Streams principles applied to general workflows. Your entire workflow is a YAML file—clean, versionable, reviewable.
What makes this approach valuable is its readability. The YAML structure forces you to separate orchestration logic from business logic, which becomes particularly useful when debugging complex workflows. Teams can collaborate more easily when the workflow definition is declarative rather than embedded in code.
But there are trade-offs—it’s still YAML. If you’ve worked with large YAML files, you know the challenges with indentation and syntax errors. While Kestra’s UI helps with validation, you’re fundamentally limited by what you can express declaratively.
Temporal: The Invincible Function
Temporal is… different. Really different. As a modern workflow orchestration tool, we actually chose it for our Knowledge-Extraction platform, and let me tell you, the learning curve is brutal. It requires a complete mental model shift from task-based systems like Celery.
Here’s what Temporal actually does: it makes your code durable.³ Your workflow is literally just code—Python, Go, Java, whatever—but it can survive anything. Server crashes, network partitions, week-long delays. The workflow just continues where it left off. It’s brilliant and maddening at the same time.
The philosophy? Code is the workflow, and the platform ensures it runs to completion no matter what. No scheduling. No task distribution. Just durable execution. Once you get it, it’s powerful. But getting there? That’s another story.
Prefect: The Pythonic Pipeline
Prefect feels like what would happen if a Python developer looked at workflow orchestration platforms like Airflow and said “this is too complicated.” Workflows are Python code with decorators. That’s it.
The platform separates observation from execution—your code runs wherever you want, but Prefect watches and coordinates everything.⁴ For Python teams, it’s immediately familiar. You can prototype in Jupyter and deploy the same code to production. There’s something beautifully simple about that.
But simplicity has trade-offs. When you need complex patterns or guarantees, you start fighting the framework. And that’s when you realize why those other platforms added all that complexity in the first place.
Architecture Under the Hood: How These Orchestrators Work
Alright, let’s get technical. Because if you don’t understand how these systems actually work, you’ll make the wrong choice and regret it for years.
Kestra’s Message-Driven Assembly Line
Kestra uses a message queue (usually Kafka) as its backbone. When a workflow triggers, it creates an Execution object that moves through the system like a product on an assembly line. The Executor reads your YAML, figures out what can run, and drops tasks onto the queue.
Workers—generic Java processes—grab tasks and execute them. They don’t know or care about your business logic. They just run what they’re told. Task outputs a file? Worker uploads it to S3 and passes a URI to the next task. Next worker downloads it automatically. You never write that code.
This decoupling is elegant. Workers can scale horizontally without knowing anything about your workflows. Add more workers, handle more load. Simple. Kestra has managed thousands of flows and millions of tasks monthly at Leroy Merlin since 2020.⁵ That’s production-tested scale.
Temporal’s Time-Traveling Replay Engine
Temporal’s architecture will mess with your head at first. Here’s what actually happens: Your workflow function starts executing. When it hits an external call (like calling an API), the SDK intercepts it, sends a command to the cluster, and the workflow pauses.
The activity runs on another worker. Result goes into the Event History. Then—and here’s where it gets weird—the workflow starts over from the beginning. But this time, when it hits that same activity call, the SDK provides the result instantly from history. The code continues past that point.
This replay mechanism is why Temporal workflows are indestructible.⁸ The entire execution history is preserved. A worker dies? Another one picks up the history and replays to exactly where things left off. It’s brilliant. It’s also why you can’t just shove application data through activities—you’ll blow up the Event History. We learned that the hard way.
Prefect’s Remote-Controlled Scripts
Prefect’s architecture is refreshingly straightforward. Your workflow is Python code. When it runs, an agent in your infrastructure spins up a container, your code executes, and the Prefect SDK phones home with status updates.
The DAG can be built dynamically as code runs. Need to spawn 100 parallel tasks based on a database query? Just write a for loop. Try doing that in YAML.
The execution environment is ephemeral—each run gets a clean slate. No state contamination, no cleanup issues. But also no built-in state management between runs unless you explicitly add it.
Show Me the Code
Let’s see what actually building a workflow looks like. Same problem, three approaches to workflow orchestration—Kestra vs Temporal vs Prefect in action:
Kestra: YAML Configuration
id: process-sales-data namespace: company.analytics inputs: - id: date type: DATE tasks: - id: extract type: io.kestra.plugin.fs.http.Download uri: "https://api.company.com/sales/{{inputs.date}}.csv" - id: transform type: io.kestra.plugin.scripts.python.Script script: | import pandas as pd df = pd.read_csv('{{outputs.extract.uri}}') df['revenue'] = df['quantity'] * df['price'] df.to_csv('{{outputDir}}/transformed.csv') - id: load type: io.kestra.plugin.jdbc.postgres.Query url: jdbc:postgresql://db:5432/analytics sql: | COPY sales_summary FROM '{{outputs.transform.uri}}' WITH (FORMAT csv, HEADER true);
The structure is clear and readable, with automatic file handling between tasks. However, implementing complex conditional logic in YAML can become challenging as workflows grow more sophisticated.
Temporal: Durable Code
from temporalio import workflow, activity import pandas as pd from datetime import timedelta @activity.defn async def extract_data(date: str) -> str: # Don't return the actual data! Return a reference response = requests.get(f"https://api.company.com/sales/{date}.csv") s3_key = f"temp/sales/{date}/{uuid.uuid4()}.csv" s3_client.put_object(Bucket='my-bucket', Key=s3_key, Body=response.content) return s3_key # Just the pointer, not the data @activity.defn async def transform_data(s3_key: str) -> str: # Download, process, upload, return new pointer obj = s3_client.get_object(Bucket='my-bucket', Key=s3_key) df = pd.read_csv(obj['Body']) df['revenue'] = df['quantity'] * df['price'] output_key = s3_key.replace('.csv', '_transformed.csv') csv_buffer = StringIO() df.to_csv(csv_buffer) s3_client.put_object(Bucket='my-bucket', Key=output_key, Body=csv_buffer.getvalue()) return output_key @workflow.defn class ProcessSalesWorkflow: @workflow.run async def run(self, date: str) -> str: # This looks simple until you realize you're managing all I/O manually s3_key = await workflow.execute_activity( extract_data, date, start_to_close_timeout=timedelta(minutes=10), retry_policy=workflow.RetryPolicy(maximum_attempts=3) ) transformed_key = await workflow.execute_activity( transform_data, s3_key, start_to_close_timeout=timedelta(minutes=10) ) # More activities for loading... return f"Processed data at {transformed_key}"
See all that S3 code? That’s what Temporal doesn’t handle for you. Every activity needs to manage its own I/O. It’s flexible, sure, but it’s also a lot of boilerplate.
Prefect: Python-Native
from prefect import flow, task import pandas as pd @task(retries=3) def extract_data(date: str) -> pd.DataFrame: response = requests.get(f"https://api.company.com/sales/{date}.csv") return pd.read_csv(io.StringIO(response.text)) @task def transform_data(df: pd.DataFrame) -> pd.DataFrame: df['revenue'] = df['quantity'] * df['price'] return df @flow(name="process-sales-data") def process_sales_flow(date: str): raw_data = extract_data(date) transformed_data = transform_data(raw_data) load_data(transformed_data)
Simple and Pythonic. However, when working with large DataFrames, you need to carefully configure result storage to handle serialization and memory management properly.
The Data Challenge: How Do These Platforms Handle Data?
This is where the rubber meets the road. How do these workflow orchestration platforms handle actual data? Let’s compare Kestra, Temporal, and Prefect:
Kestra: Automated Data Handling
Kestra’s data handling is impressively automated.⁷ When a task outputs a file, it’s automatically uploaded to configured storage (S3, GCS, etc.). The next task receives a URI and the file is automatically downloaded before execution. You write code as if files are local while Kestra manages the complexity.
For data pipelines, this automation saves significant development time. No S3 client code, no credential management, no cleanup logic. The trade-off is that you’re working within Kestra’s abstraction. If you need custom caching logic, special compression, or streaming processing, you’ll need to work within the framework’s constraints.
Temporal: DIY Everything
With Temporal, you handle everything yourself. And I mean everything. We spent weeks building a proper abstraction layer for file handling in our Knowledge-Extraction platform because we couldn’t pass actual data through activities without killing the Event History.¹⁰
Every activity uploads its results somewhere (S3, Redis, wherever) and returns a pointer. The next activity fetches it. You need error handling for the upload. Error handling for the download. Cleanup logic. It’s exhausting.
But here’s the thing: you have complete control. Need to stream process a 100GB file? You can. Want to implement custom compression? Go ahead. Temporal doesn’t care how you move data, which is both its strength and weakness.
Prefect: Configurable Storage
Prefect provides Result Storage blocks as a middle ground.¹² Mark a task with persist_result=True and it handles serialization and storage. The challenge is that it uses pickle by default, which can significantly increase file sizes and has limitations with certain object types.
You can configure different serializers and storage backends, but this requires additional configuration management. It’s a flexible approach that works well for Python-centric workflows with occasional persistence needs.
Extensibility Models
Let’s discuss how each platform handles extensions and custom logic.
Kestra: Plugin Ecosystem
Kestra’s plugin architecture allows extending functionality through Java-based plugins. The ecosystem includes official plugins for major cloud providers, databases, and messaging systems. Creating custom plugins requires Java knowledge but provides deep integration with the execution engine.
Temporal: SDK-Based Extension
Temporal’s extension model centers around its SDKs. Custom interceptors, custom data converters, and workflow middlewares enable sophisticated patterns. The multi-language SDK support means teams can use their preferred language while maintaining interoperability.
Prefect: Pythonic Blocks
Prefect’s Block system provides reusable, configurable components. From storage backends to notification services, blocks encapsulate configuration and logic. Python developers can easily create custom blocks, maintaining the platform’s accessible philosophy.
Performance & Scalability: Workflow Orchestration Benchmarks
Let’s talk numbers. Because when you’re processing millions of tasks, architecture matters.
Kestra: Built for Throughput
Kestra’s event-driven architecture with Kafka can handle massive scale. Workers poll the queue, execute tasks, report results. Need more throughput? Add workers. The queue provides natural backpressure handling.
We’ve seen deployments handling thousands of workflows with millions of tasks monthly. The bottleneck is usually the database storing execution history, not the execution engine itself. For batch processing and ETL workloads, it’s hard to beat.
Temporal: Reliability Over Speed
Temporal isn’t winning any throughput benchmarks. That’s not the point. Every workflow execution maintains a complete event history. Every state change is persisted. Every action is replayable.⁹
This overhead means Temporal processes fewer workflows per second than Kestra or Prefect. But those workflows are indestructible. For our Knowledge-Extraction platform where each workflow represents hours of LLM processing, that reliability is worth the performance cost.
Also, Temporal workflows can run for literally months. Try that with a traditional task queue.
Prefect: Flexible but Unpredictable
Prefect’s performance depends entirely on your deployment. Running on Kubernetes with 100 agents? Fast. Running on a single VM? Not so much. The ephemeral execution model means each flow run has startup overhead.
But here’s what’s nice: different flows can have different infrastructure requirements. CPU-bound processing on big machines, API calls on small ones. You’re not locked into a one-size-fits-all worker pool.
Making the Decision: Which Workflow Orchestrator Is Best?
After building production systems with these platforms, here’s my honest take on when to use each.
Is Kestra Better Than Temporal?
Choose Kestra When: You’re building data pipelines where moving files between stages is common. Your team includes both developers and analysts who need to understand workflows. You want GitOps-style workflow management with declarative definitions. Kestra excels for ETL, batch processing, and scenarios where declarative configuration helps maintain clean architecture. The automatic file handling is particularly valuable for data-heavy workloads.
However, Kestra may not be the best choice if you need highly complex dynamic logic or if your workflows are primarily API orchestration without significant file I/O.
Is Temporal Better Than Prefect?
Choose Temporal When: You’re building mission-critical systems that absolutely cannot lose data. We chose it for our AI platform because when you’re running expensive LLM operations, you cannot afford to lose progress due to a crash.⁶
The learning curve is significant—expect a month before your team is productive. The manual I/O handling requires extra work. The replay model takes time to understand. But once it clicks, you’ll have workflows that are incredibly resilient.
Temporal might not be the right fit for simple ETL or if your team doesn’t have strong software engineering experience. The complexity overhead may not be justified for basic automation tasks.
Which Workflow Orchestrator Is Easiest to Learn?
Choose Prefect When: Your team is Python-native and you need to move fast. If you’re prototyping in Jupyter notebooks and want to deploy the same code to production, Prefect is your friend. The learning curve is basically zero for Python developers.
It’s well-suited for ML pipelines, data science workflows, and scenarios requiring rapid iteration. The dynamic DAG construction enables patterns that are difficult to implement in more rigid systems.
Consider alternatives if you need strong guarantees about execution, complex retry semantics, or if your workflows extend beyond Python.
Real-World Scenarios
Let me share what we’ve actually seen work (and fail) in production.
Multi-Stage ETL Pipeline
Winner: Kestra – In a financial services deployment processing daily transaction data with multiple teams owning different transformation stages, Kestra’s transparent file handling eliminated significant S3 boilerplate code. The YAML format made workflows reviewable through standard git processes, satisfying both engineering and compliance requirements.
Order Processing System
Winner: Temporal – An e-commerce platform orchestrating inventory, payment, and shipping services benefited from Temporal’s resilience. During a payment provider outage, Temporal workflows automatically paused and resumed without manual intervention or data loss. The complete Event History provided the audit trails required for compliance.
ML Experimentation Pipeline
Winner: Prefect – A data science team running hyperparameter searches needed to spawn varying numbers of training jobs based on search space. Prefect’s dynamic DAGs made this straightforward—using simple Python loops to create tasks. The ability to prototype in notebooks and deploy the same code accelerated their development cycle.
Cross-Cloud Data Synchronization
Winner: Kestra – A media company synchronizing content across AWS, GCP, and Azure leveraged Kestra’s event-driven triggers for millisecond response times. The built-in cloud storage plugins eliminated custom authentication code, while the YAML routing logic remained maintainable as complexity grew. Building equivalent functionality in code-based orchestrators would require significantly more development effort.
The Future of Workflow Orchestration in 2025
The workflow orchestration landscape in 2025 is evolving rapidly. Event-driven architectures are becoming the default. Real-time processing is merging with batch. AI is entering the picture, though mostly as hype for now.
We’re seeing organizations adopt multiple orchestrators for different use cases. Kestra for data pipelines, Temporal for microservices, Prefect for ML. This isn’t failure—it’s specialization. Just like you don’t use Postgres for everything, you shouldn’t expect one orchestrator to solve all problems.
The real trend? Declarative configuration is winning for standard patterns while code-based orchestration dominates complex logic. Platforms that can bridge both worlds will thrive.
The Bottom Line
There’s no perfect workflow orchestration platform. After comparing Kestra vs Temporal vs Prefect in production, we learned this the hard way building our Knowledge-Extraction platform. Temporal’s complexity nearly killed us in the beginning, but now it’s the backbone of our system. We’re still evaluating whether Prefect might be simpler for certain workflows—more on that soon.
Here’s what matters: Kestra excels at data movement with minimal code. Temporal provides unmatched reliability at the cost of complexity. Prefect offers Python-native simplicity but with fewer guarantees.
Pick based on your team’s strengths and your actual requirements for 2025 and beyond, not marketing promises. And whatever you choose, invest in understanding its architecture deeply. Because when things break at 3 AM—and they will—you’ll need to know why.
The workflow orchestration landscape in 2025 has exploded from simple cron replacements to sophisticated distributed systems. Choose wisely. Your future self will thank you.
References
- Martin, A., ‘State of Open Source Workflow Orchestration Systems 2025’, Practical Data Engineering, 2 February 2025, https://www.pracdata.io/p/state-of-workflow-orchestration-ecosystem-2025, accessed 10 February 2025.
- Kestra Technologies, ‘Kestra Documentation: Architecture Overview’, Kestra.io, 2024, https://kestra.io/docs/architecture, accessed 15 January 2025.
- Temporal Technologies, ‘Understanding Temporal: Durable Execution’, Temporal Documentation, 2024, https://docs.temporal.io/concepts/what-is-temporal, accessed 15 January 2025.
- Prefect Technologies, ‘Why Prefect: Modern Workflow Orchestration’, Prefect Documentation, 2024, https://docs.prefect.io/latest/concepts/overview/, accessed 15 January 2025.
- Leroy Merlin Tech Team, ‘Scaling Data Pipelines with Kestra at Leroy Merlin’, Leroy Merlin Tech Blog, March 2023.
- Fateev, M., and Abbas, S., ‘Building Reliable Distributed Systems with Temporal’, in Proceedings of QCon San Francisco, October 2023.
- Kestra Technologies, ‘Declarative Data Orchestration with YAML’, Kestra Features, 2024, https://kestra.io/features/declarative-data-orchestration, accessed 15 January 2025.
- Temporal Technologies, ‘Event History and Workflow Replay’, Temporal Documentation, 2024, https://docs.temporal.io/workflows#event-history, accessed 15 January 2025.
- Deng, D., ‘Building Resilient Microservice Workflows with Temporal’, SafetyCulture Engineering Blog, Medium, 13 February 2023, https://medium.com/safetycultureengineering/building-resilient-microservice-workflows-with-temporal-a9637a73572d, accessed 20 January 2025.
- Waehner, K., ‘The Rise of the Durable Execution Engine in Event-driven Architecture’, Kai Waehner’s Blog, 5 June 2025, https://www.kai-waehner.de/blog/2025/06/05/the-rise-of-the-durable-execution-engine-temporal-restate-in-an-event-driven-architecture-apache-kafka/, accessed 10 June 2025.
- GitHub, ‘Awesome Workflow Engines: A Curated List’, GitHub Repository, 2024, https://github.com/meirwah/awesome-workflow-engines, accessed 15 January 2025.
- Prefect Technologies, ‘Result Storage and Serialization’, Prefect Documentation, 2024, https://docs.prefect.io/latest/concepts/results/, accessed 15 January 2025.
- Netflix Technology Blog, ‘Maestro: Netflix’s Workflow Orchestrator’, Netflix TechBlog, July 2024.
![Long Document Classification Benchmark 2025: XGBoost vs BERT vs Traditional ML [Complete Guide]](https://procycons.com/wp-content/uploads/2025/07/long-document-classification.jpg)