Artikel maschinell aus dem Englischen übersetzt
Was ist Klassifikation langer Dokumente?
Die Klassifikation langer Dokumente ist ein spezialisiertes Teilgebiet der Dokumentenklassifikation im Natural Language Processing (NLP), das sich auf die Kategorisierung von Dokumenten mit 1.000+ Wörtern (2+ Seiten) konzentriert, wie etwa wissenschaftliche Arbeiten, Rechtsverträge und technische Berichte. Anders als bei kurzen Texten stellen lange Dokumente besondere Herausforderungen dar: begrenzte Eingabelängen (z. B. 512 Token bei BERT), Verlust kontextueller Kohärenz beim Aufteilen des Dokuments, hohe Rechenkosten und die Notwendigkeit komplexer Label-Strukturen wie Multi-Label- oder hierarchische Klassifikation.
Zusammenfassung
Diese Benchmark-Studie evaluiert verschiedene Ansätze zur Klassifikation langer Dokumente (7.000-14.000 Wörter ≈ 14-28 Seiten ≈ kurze bis mittlere wissenschaftliche Arbeiten) in 11 akademischen Kategorien. XGBoost erwies sich als vielseitigste Lösung und erreichte F1-Werte (ausgewogenes Maß aus Precision und Recall) von 75-86 mit vernünftigen Rechenanforderungen (Chen und Guestrin, 2016). Logistic Regression bietet das beste Effizienz-Leistungs-Verhältnis für ressourcenbeschränkte Umgebungen mit Trainingszeiten unter 20 Sekunden bei konkurrenzfähiger Genauigkeit (Genkin, Lewis und Madigan, 2005). Überraschenderweise schnitt RoBERTa-base deutlich schlechter ab trotz seines allgemeinen Rufs, während traditionelle maschinelle Lernverfahren sich als hochgradig konkurrenzfähig gegenüber fortgeschrittenen Transformer-Modellen erwiesen (Liu et al., 2019).
Unsere Experimente analysierten 27.000+ Dokumente in vier Komplexitätskategorien, von einfachem Keyword-Matching bis hin zu Large Language Models, und zeigten, dass traditionelle ML-Methoden oft ausgefeiltere Transformer übertreffen und dabei 10x weniger Rechenressourcen verwenden. Diese überraschenden Ergebnisse stellen die gängige Annahme in Frage, dass komplexe Modelle für die Klassifikation langer Dokumente notwendig sind.
Schnelle Empfehlungen
- Insgesamt beste: XGBoost (F1: 86%, schnelles Training)
- Effizienteste: Logistic Regression (trainiert in <20s)
- Bei verfügbarer GPU: BERT-base (Devlin et. al, 2019) (F1: 82%, aber langsamer)
- Zu vermeiden: Keyword-basierte Methoden, RoBERTa-base
Studienmethodik & Glaubwürdigkeit
- Datensatzgröße: 27.000+ Dokumente in 11 akademischen Kategorien [Download]
- Hardware-Spezifikation: 15x vCPUs, 45GB RAM, NVIDIA Tesla V100S 32GB
- Reproduzierbarkeit: Alle Code und Konfigurationen sind auf GitHub verfügbar
Wichtige Forschungsergebnisse (Verifizierte Ergebnisse)
- XGBoost erreichte einen 86% F1-Wert bei 27.000 akademischen Dokumenten
- Traditionelle ML-Methoden trainieren 10x schneller als Transformer-Modelle
- BERT benötigt 2GB+ GPU-Speicher vs 100MB RAM für XGBoost
- RoBERTa-base erreichte nur einen 57% F1-Wert und blieb damit hinter den Erwartungen bei kleinen Datensätzen zurück
- Das Training transformer-basierter Modelle auf dem vollständigen Datensatz ist aufgrund der extrem langen Trainingszeit (über 4 Stunden) nicht gerechtfertigt. Bemerkenswerterweise steigt mit wachsendem Datenvolumen die Modellkomplexität und die Trainingszeit exponentiell an
Wie man die richtige Dokumentenklassifikationsmethode für lange Dokumente mit einer kleinen Anzahl von Beispielen (~100 bis 150 Beispiele) wählt
| Kriterium | Logistic Regression | XGBoost | BERT-base |
|---|---|---|---|
| Bester Anwendungsfall | Ressourcenbeschränkt | Produktionssysteme | Forschungsanwendungen |
| Trainingszeit | 3 Sekunden | 35 Sekunden | 23 Minuten |
| Genauigkeit (F1 %) | 79 | 81 | 82 |
| Speicheranforderungen | 50MB RAM | 100MB RAM | 2GB GPU RAM |
| Implementierungsschwierigkeit | Niedrig | Mittel | Hoch |
Inhaltsverzeichnis
- Einführung
- Klassifikationsmethoden: Einfach bis Komplex
- Technische Spezifikationen
- Ergebnisse und Analyse
- Bereitstellungs-Szenarien
- Häufig gestellte Fragen
- Fazit
1. Einführung
Die Klassifikation langer Dokumente ist ein spezialisiertes Teilgebiet der Dokumentenklassifikation im Natural Language Processing (NLP). Im Kern geht es bei der Dokumentenklassifikation darum, einem gegebenen Dokument basierend auf seinem Inhalt eine oder mehrere vordefinierte Kategorien oder Labels zuzuweisen. Dies ist eine grundlegende Aufgabe für die effiziente Organisation, Verwaltung und Auffindung von Informationen in verschiedenen Bereichen, von Recht und Gesundheitswesen bis hin zu News und Kundenbewertungen.
Bei der Klassifikation langer Dokumente bezieht sich „lang“ auf die erhebliche Länge der zu verarbeitenden Dokumente. Während kurze Texte wie Tweets, Schlagzeilen oder einzelne Sätze nur wenige Wörter enthalten, können lange Dokumente mehrere Absätze, ganze Artikel, Bücher oder sogar Rechtsverträge umfassen. Diese Dokumentenlänge führt zu besonderen Herausforderungen, mit denen traditionelle Textklassifikationsmethoden oft Schwierigkeiten haben.
Hauptherausforderungen bei der Klassifikation langer Dokumente
- Kontextuelle Informationen: Lange Dokumente enthalten deutlich reichhaltigere und komplexere Kontexte. Sie genau zu verstehen und zu klassifizieren erfordert die Verarbeitung von Informationen, die sich über mehrere Sätze und Absätze erstrecken, nicht nur wenige Keywords.
- Rechenkomplexität: Viele fortgeschrittene NLP-Modelle, insbesondere Transformer-basierte wie BERT, haben Grenzen bei der maximalen Eingabelänge (so genannte Tokens), die sie effizient verarbeiten können. Ihre Self-Attention-Mechanismen sind zwar mächtig für die Erfassung von Wortbeziehungen, werden aber rechnerisch teuer (O(N²)-Komplexität – wächst exponentiell mit der Dokumentenlänge) und speicherintensiv beim Umgang mit sehr langen Texten.
- Informationsdichte und -spärlichkeit: Obwohl lange Dokumente viele Informationen enthalten, sind die wichtigsten Features für die Klassifikation oft spärlich verteilt. Dadurch fällt es Modellen schwer, diese wichtigen Signale zwischen großen Mengen weniger relevanter Inhalte zu erkennen und sich darauf zu konzentrieren.
- Erhaltung der Kohärenz: Ein gängiger Ansatz ist es, lange Dokumente in kleinere Segmente aufzuteilen. Dies kann jedoch den Fluss und Kontext unterbrechen, was es für Modelle schwieriger macht, die Gesamtbedeutung zu erfassen und genaue Klassifikationen vorzunehmen.
Studienziele
In dieser Benchmark-Studie evaluieren wir verschiedene Methoden zur Klassifikation langer Dokumente aus praktischer sowie entwicklungsorientierter Perspektive. Unser Ziel ist es zu identifizieren, welcher Ansatz die einzigartigen Herausforderungen der Verarbeitung langer Dokumente am besten bewältigt, basierend auf folgenden Kriterien:
- Effizienz: Modelle sollten lange Dokumente effizient in Bezug auf Zeit und Speicher verarbeiten können
- Genauigkeit: Modelle sollten Dokumente auch bei großer Länge genau klassifizieren können
- Robustheit: Modelle sollten robust gegenüber variierenden Dokumentenlängen und verschiedenen Arten der Informationsorganisation sein
2. Klassifikationsmethoden: Einfach bis Komplex
Dieser Abschnitt präsentiert vier Kategorien von Klassifikationsmethoden, die von einfachem Keyword-Matching bis hin zu ausgeklügelten Sprachmodellen reichen. Jede Methode repräsentiert unterschiedliche Kompromisse zwischen Genauigkeit, Geschwindigkeit und Umsetzungsaufwand.
2.1 Einfache Methoden (Kein Training erforderlich)
Diese Methoden sind schnell zu implementieren und funktionieren gut, wenn die Dokumente relativ einfach und nicht strukturell komplex sind. Typischerweise regelbasiert, musterbasiert oder Keyword-basiert benötigen sie keine Trainingszeit, was sie besonders robust gegenüber Änderungen in der Anzahl der Labels macht.
Wann zu verwenden: Bekannte Dokumentstrukturen, schnelle Prototypenerstellung oder wenn keine Trainingsdaten verfügbar sind.
Hauptvorteil: Null Trainingszeit und hohe Interpretierbarkeit.
Haupteinschränkung: Schlechte Leistung bei komplexen oder nuancierten Klassifikationsaufgaben.
Keyword-basierte Klassifikation
Der Prozess beginnt mit der Extraktion repräsentativer Keywords für jede Kategorie aus dem Dokumentensatz. Während des Tests (oder der Vorhersage) folgt die Klassifikation diesen grundlegenden Schritten:
- Tokenisierung des Dokuments
- Zählung der Keyword-Treffer für jede Kategorie
- Zuordnung des Dokuments zur Kategorie mit der höchsten Trefferanzahl oder Keyword-Dichte
Fortgeschrittenere Tools wie YAKE (Yet Another Keyword Extractor) [5] können zur Automatisierung der Keyword-Extraktion verwendet werden. Zusätzlich können, wenn Kategorienamen im Voraus bekannt sind, externe Keywords – solche, die nicht in den Dokumenten gefunden werden – mit Hilfe intelligenter Modelle zu den Keyword-Sets hinzugefügt werden.
Keyword-basierte Klassifikationsdiagramm

TF-IDF (Term Frequency-Inverse Document Frequency) + Ähnlichkeit
Obwohl es TF-IDF-Vektoren verwendet, erfordert es kein Training eines maschinellen Lernmodells. Stattdessen wählen Sie einige repräsentative Dokumente für jede Kategorie aus – oft sind nur 2 oder 3 Beispiele pro Kategorie ausreichend – und berechnen deren TF-IDF-Vektoren, die die Wichtigkeit jedes Wortes innerhalb des Dokuments relativ zum Rest des Korpus widerspiegeln.
Als nächstes berechnen Sie für jede Kategorie einen mittleren TF-IDF-Vektor, um ein typisches Dokument in dieser Klasse zu repräsentieren. Beim Testen wandeln Sie das neue Dokument in einen TF-IDF-Vektor um und berechnen seine Kosinus-Ähnlichkeit mit dem mittleren Vektor jeder Kategorie. Die Kategorie mit dem höchsten Ähnlichkeitswert wird als vorhergesagtes Label ausgewählt.
Dieser Ansatz ist besonders effektiv für lange Dokumente, da er den gesamten Inhalt berücksichtigt, anstatt sich auf eine begrenzte Anzahl von Keywords zu konzentrieren. Er ist auch robuster als einfaches Keyword-Matching und vermeidet dennoch die Notwendigkeit für überwachtes Training.
TF-IDF-basiertes Klassifikationsdiagramm

Empfohlenes Vorgehen: Wenn einfache Methoden Ihre Genauigkeitsanforderungen erfüllen, fahren Sie mit der Keyword-Extraktion mit YAKE oder manueller Auswahl fort. Andernfalls ziehen Sie traditionelle ML-Verfahren für bessere Leistung in Betracht.
Fazit: Einfache Methoden bieten schnelle Implementierung und null Trainingszeit, leiden aber unter schlechter Genauigkeit bei komplexen Klassifikationsaufgaben. Am besten geeignet für gut strukturierte Dokumente mit klaren Keyword-Mustern.
2.2 Traditionelle ML-Verfahren
Nachdem wir einfache Methoden behandelt haben, untersuchen wir nun traditionelle ML-Verfahren, die Training erfordern, aber deutlich bessere Leistung bieten.
Wann zu verwenden: Wenn Sie gelabelte Trainingsdaten haben und zuverlässige, schnelle Klassifikation benötigen.
Hauptvorteil: Ausgezeichnete Balance zwischen Genauigkeit, Geschwindigkeit und Ressourcenanforderungen.
Haupteinschränkung: Erfordert Feature Engineering und Trainingsdaten.
Eine der einfachsten und bewährtesten Methoden für Dokumentenklassifikation – besonders als Referenzwert – ist die Kombination aus TF-IDF-Vektorisierung mit traditionellen maschinellen Lernklassifikatoren wie Logistic Regression, Support Vector Machines (SVMs) oder XGBoost. Trotz ihrer Einfachheit bleibt diese Methode eine konkurrenzfähige Option für viele reale Anwendungen, besonders wenn Interpretierbarkeit, Geschwindigkeit und einfache Bereitstellung priorisiert werden.
Methodenüberblick
Das Verfahren ist einfach: Der Dokumententext wird mit TF-IDF in eine numerische Form umgewandelt, die erfasst, wie wichtig ein Wort relativ zu einem Korpus ist. Dies erzeugt einen spärlichen Vektor gewichteter Wortzählungen.
Der resultierende Vektor wird dann an einen klassischen Klassifikator weitergegeben, typischerweise:
- Logistic Regression für lineare Trennbarkeit und schnelles Training
- SVM für komplexere Grenzen
- XGBoost für hochperformante, baumbasierte Modellierung
Das Modell lernt, Wortpräsenz- und Häufigkeitsmuster mit den gewünschten Output-Labels zu verknüpfen (z.B. Themenkategorien oder Dokumenttypen).
Umgang mit langen Dokumenten
Standardmäßig kann TF-IDF das gesamte Dokument auf einmal verarbeiten, was es für lange Texte ohne die Notwendigkeit komplexer Segmentierungs- oder Truncation-Strategien geeignet macht. Wenn Dokumente jedoch extrem lang sind (z.B. über 5.000-10.000 Wörter), kann es vorteilhaft sein:
- Das Dokument in kleinere Segmente aufzuteilen (z.B. 1.000-2.000 Wörter)
- Jeden Abschnitt einzeln zu klassifizieren
- Und dann Ergebnisse mit Mehrheitswahl oder durchschnittlichen Konfidenz-Werten zu aggregieren
Diese Segmentierungsstrategie kann die Stabilität verbessern und spärliche Vektorprobleme mildern, während sie rechnerisch effizient bleibt.
ML-basiertes Klassifikationsdiagramm

Empfohlenes Vorgehen: Beginnen Sie mit Logistic Regression für Referenz-Leistung, dann probieren Sie XGBoost für optimale Genauigkeit. Verwenden Sie 5-fache Kreuzvalidierung mit stratifiziertem Sampling für robuste Evaluation.
Fazit: Traditionelle ML-Verfahren zeigen die beste Balance zwischen Genauigkeit und Effizienz. XGBoost liefert konstant Spitzenleistung, während Logistic Regression in ressourcenbeschränkten Umgebungen glänzt.
2.3 Transformer-basierte Verfahren
Über traditionelle Ansätze hinausgehend erkunden wir transformer-basierte Methoden, die vortrainiertes Sprachverständnis nutzen.
Wann zu verwenden: Wenn maximale Genauigkeit benötigt wird und GPU-Ressourcen verfügbar sind.
Hauptvorteil: Tiefes Sprachverständnis und hohes Genauigkeitspotential.
Haupteinschränkung: Rechenintensität und 512-Token-Limit, das Segmentierung erfordert.
Für viele Klassifikationsaufgaben mit mäßig langen Dokumenten – typischerweise im Bereich von 300 bis 1.500 Wörtern – stellen feinabgestimmte Transformer-Modelle wie BERT, DistilBERT (Sanh et al., 2019) und RoBERTa eine hocheffektive und zugängliche Lösung dar. Diese Modelle schlagen eine Brücke zwischen traditionellen maschinellen Lernansätzen und großskaligen Modellen wie Longformer oder GPT-4.
Architektur und Training
Im Kern sind diese Modelle vortrainierte Sprachmodelle, die allgemeine sprachliche Muster aus großen Korpora wie Wikipedia und BookCorpus gelernt haben. Wenn sie für Dokumentenklassifikation feinabgestimmt werden, wird die Architektur durch Hinzufügung eines einfachen Klassifikationskopfes – meist eine dichte Schicht – auf der gepoolten Ausgabe des Transformers erweitert.
Die Feinabstimmung beinhaltet das Training dieses erweiterten Modells auf einem gelabelten Datensatz für eine spezifische Aufgabe, wie die Klassifikation von Berichten in Kategorien wie Finanzen, Nachhaltigkeit oder Recht. Während des Trainings passt das Modell sowohl den Klassifikationskopf als auch (optional) die internen Transformer-Gewichte basierend auf aufgabenspezifischen Beispielen an.
Umgang mit Längenbeschränkungen
Eine Schlüsseleinschränkung von Standard-Transformern wie BERT und DistilBERT ist, dass sie nur Sequenzen bis zu 512 Token unterstützen. Für lange Dokumente muss diese Beschränkung angegangen werden durch:
- Truncation: Einfaches Abschneiden des Textes nach den ersten 512 Token. Schnell, aber kann kritische Informationen später im Dokument ignorieren.
- Segmentierung: Aufteilen des Dokuments in überlappende oder sequentielle Segmente, individuelle Klassifikation jedes Abschnitts und anschließende Aggregation der Vorhersagen mit Mehrheitswahl, durchschnittlicher Konfidenz oder attention-basierter Gewichtung.
- Preprocessing und Datenvorbereitung: Bei diesem Ansatz werden lange Dokumente zuerst in kürzere Texte (bis zu 512 Token) aufgebrochen mithilfe von Vorverarbeitungstechniken wie Keyword-Extraktion oder Zusammenfassung. Während diese Methoden möglicherweise etwas Kohärenz zwischen Segmenten opfern, bieten sie schnellere Trainings- und Klassifikationszeiten.
Während die Segmentierung Komplexität hinzufügt, ermöglicht sie diesen Modellen, Dokumente mit mehreren tausend Wörtern zu verarbeiten, während vernünftige Leistung beibehalten wird.
Transformer-basiertes Klassifikationsdiagramm

Empfohlenes Vorgehen: Beginnen Sie mit DistilBERT für schnelleres Training, dann upgraden Sie zu BERT, wenn Genauigkeitsgewinne die Rechenkosten rechtfertigen. Implementieren Sie überlappende Segmentierungsstrategien für Dokumente über 512 Token.
Fazit: Transformer-Methoden bieten hohe Genauigkeit, erfordern aber erhebliche Rechenressourcen. BERT-base liefert gute Leistung, während RoBERTa-base überraschend unterperformt, was die Wichtigkeit empirischer Evaluation über Reputation hinaus betont.
2.4 Large Language Models
Schließlich untersuchen wir die ausgefeiltesten Ansätze mit Large Language Models für instruktionsbasierte Klassifikation.
Wann zu verwenden: Zero-Shot-Klassifikation, extrem lange Dokumente oder wenn Trainingsdaten begrenzt sind.
Hauptvorteil: Kein Training erforderlich, verarbeitet sehr lange Kontexte, hohe Genauigkeit.
Haupteinschränkung: Hohe API-Kosten, langsamere Inferenz und Internetverbindung erforderlich.
Diese Methoden sind mächtige Modelle, die komplexe Dokumente mit minimalem oder keinem Training verstehen können. Sie eignen sich für Aufgaben wie instruktionsbasierte oder Zero-Shot-Klassifikation.
API-basierte Klassifikation
OpenAI GPT-4 / Claude / Gemini 1.5: Dieser Ansatz nutzt die Instruktionsbefolgungsfähigkeit von Modellen wie GPT-4, Claude und Gemini durch API-Aufrufe. Diese Modelle können lange Kontext-Eingaben verarbeiten – bis zu 128.000 Token in einigen Fällen (was etwa 300+ Seiten Text ≈ mehreren wissenschaftlichen Arbeiten entspricht).
Die Methode ist konzeptionell einfach: Sie geben dem Modell den Dokumententext (oder einen erheblichen Teil davon) zusammen mit einem Prompt wie:
„Du bist ein Dokumentenklassifikationsassistent. Klassifiziere das unten stehende Dokument in eine der folgenden Kategorien: [Finanzen, Recht, Nachhaltigkeit].“
Nach der Eingabe analysiert das LLM das Dokument in Echtzeit und gibt ein Label oder sogar einen Konfidenz-Wert zurück, oft mit einer Erklärung.
LLM-basiertes Klassifikationsdiagramm

RAG-erweiterte Klassifikation
LLMs kombiniert mit RAG (Retrieval-Augmented Generation): Retrieval-Augmented Generation (RAG) ist ein fortgeschritteneres Architekturmuster, das ein vektorbasiertes Retrieval-System mit einem LLM kombiniert. So funktioniert es bei der Klassifikation:
- Zuerst wird das lange Dokument in kleinere, semantisch sinnvolle Abschnitte aufgeteilt (z.B. nach Abschnitten, Überschriften oder Absätzen)
- Jeder Abschnitt wird mit einem Embedding-Modell (wie OpenAIs text-embedding oder SentenceTransformers) in einen dichten Vektor eingebettet
- Diese Vektoren werden in einer Vektordatenbank (wie FAISS oder Pinecone) gespeichert
- Wenn Klassifikation benötigt wird, ruft das System nur die relevantesten Dokumentenabschnitte ab und übergibt sie an ein LLM (wie GPT-4) zusammen mit einer Klassifikationsanweisung
LLM-basiertes + RAG Klassifikationsdiagramm
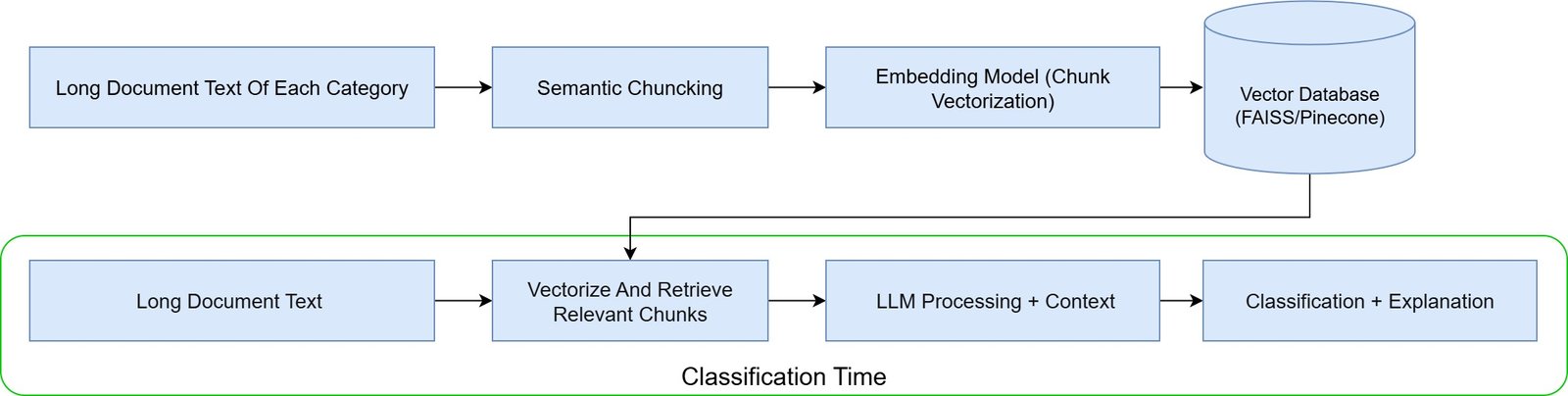
Diese Methode ermöglicht es Ihnen, lange Dokumente effizient und skalierbar zu verarbeiten, während Sie trotzdem von der Kraft großer Modelle profitieren.
Empfohlenes Vorgehen: Beginnen Sie mit einfacheren Prompting-Strategien, bevor Sie RAG implementieren. Berücksichtigen Sie die Kosteneffizienz im Vergleich zu feinabgestimmten Modellen für Ihren spezifischen Anwendungsfall.
Fazit: LLM-Methoden bieten mächtige Zero-Shot-Fähigkeiten für lange Dokumente, bringen aber hohe API-Kosten und Latenz mit sich. Am besten geeignet für Szenarien, in denen Trainingsdaten begrenzt sind oder extrem lange Kontextverarbeitung erforderlich ist.
2.5 Modellvergleichsübersicht
Die folgende Tabelle bietet einen umfassenden Überblick über alle Klassifikationsmethoden und vergleicht ihre Fähigkeiten, Ressourcenanforderungen und optimalen Anwendungsfälle, um bei der Auswahl zu helfen.
| Methoden | Modell/Klasse | Max Tokens | Segmentierung nötig? | Einfachheit (1-5) | Genauigkeit (1-5) | Ressourcenverbrauch | Am besten für |
|---|---|---|---|---|---|---|---|
| Einfach | Keyword/Regex-Regeln | ∞ | Nein | 1 (Einfach) | 2 (Niedrig) | Minimal CPU & RAM | Bekannte Struktur/Formate (z.B. Recht) |
| TF-IDF + Ähnlichkeit | ∞ | Nein | 2 | 2-3 | Niedrig CPU, ~150MB RAM | Labeling basierend auf wenigen Beispielen | |
| Traditionell | TF-IDF + ML | ∞ (ganzes Dokument) | Optional | 1 (Einfach) | 3 (Gut) | Niedrig CPU, ~100MB RAM | Schnelle Referenzwerte, Prototyping |
| Transformer-basiert | BERT / DistilBERT / RoBERTa | 512 Tokens | Ja | 3 | 4 (Hoch) | Benötigt GPU / ~1-2GB RAM | Kurze/mittlere Texte, Feinabstimmung möglich |
| Longformer / BigBird | 4.096-16.000 | Nein | 4 | 5 (Höchste) | GPU (8GB+), ~3-8GB RAM | Lange Berichte, tiefe Genauigkeit benötigt | |
| Large Language Models | GPT-4 / Claude / Gemini | 32k-128k Tokens | Nein oder leicht | 4 (API-basiert) | 5 (Höchste) | Hohe Kosten, API-Limits | Zero-Shot-Klassifikation großer Dokumente |
Fazit: Traditionelles ML (XGBoost) übertrifft oft fortgeschrittene Transformer bei 10x weniger Ressourcenverbrauch.
2.6 Referenzierte Datensätze & Standards
Die folgenden Datensätze bieten exzellente Benchmarks für das Testen von Klassifikationsmethoden für lange Dokumente:
| Datensatz | Ø Länge | Bereich | Seitenlänge | Kategorien | Quelle |
|---|---|---|---|---|---|
| S2ORC | 3k-10k Tokens | Akademisch | 6-20 | Dutzende | Semantic Scholar |
| ArXiv | 4k-14k Wörter | Akademisch | 8-28 | 38+ | arXiv.org |
| BillSum | 1,5k-6k Tokens | Regierung | 3-12 | Policy-Kategorien | FiscalNote |
| GOVREPORT | 4k-10k Tokens | Regierung/Finanzen | 8-20 | Verschiedene | Regierungsbehörden |
| CUAD | 3k-10k Tokens | Recht | 6-20 | Vertragsklauseln | Atticus Project |
| MIMIC-III | 2k-5k Tokens | Medizin | 3-10 | Klinische Notizen | PhysioNet |
| SEC 10-K/Q | 10k-50k Wörter | Finanzen | 20-100 | Unternehmen/Bereich | SEC EDGAR |
Kontext: Alle Datensätze sind öffentlich verfügbar mit entsprechenden Lizenzvereinbarungen. Trainingszeiten variieren von 2 Stunden (kleine Datensätze) bis 2 Tage (große Datensätze) auf Standard-Hardware.
3. Technische Spezifikationen
3.1 Evaluationskriterien
Genauigkeitsbewertung: Verwendung von Accuracy, Precision (echte Positive / vorhergesagte Positive), Recall (echte Positive / tatsächliche Positive) und F1-Wert (harmonisches Mittel aus Precision und Recall) Kriterien.
Ressourcen- und Zeitbewertung: Die Menge an Zeit und Ressourcen, die während Training und Testing verwendet werden.
3.2 Experimenteinstellungen
Hardware-Konfiguration: 15x vCPUs, 45GB RAM, NVIDIA Tesla V100S 32GB.
Evaluationsmethodik: 5-fache Kreuzvalidierung mit stratifiziertem Sampling wurde verwendet, um robuste statistische Evaluation sicherzustellen.
Software-Bibliotheken: scikit-learn 1.3.0, transformers 4.38.0, PyTorch 2.7.1, XGBoost 3.0.2
3.2.1 Datensatzauswahl
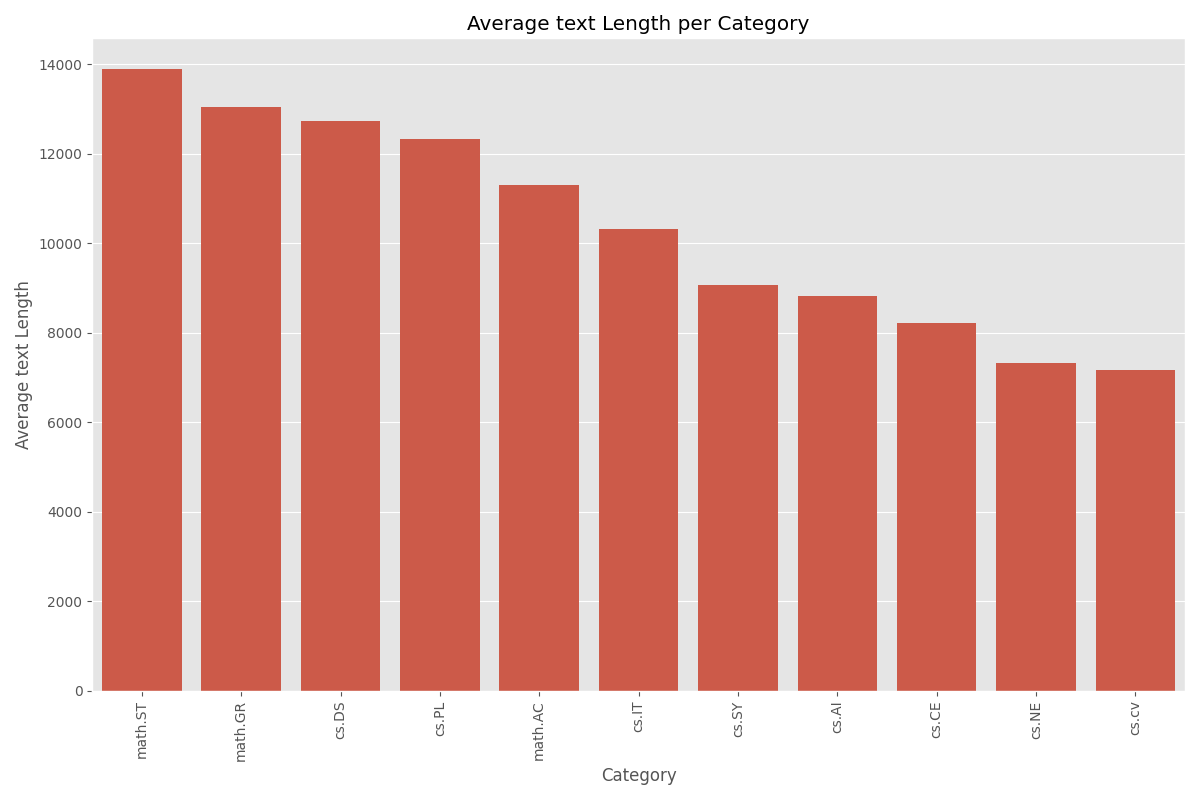
Wir verwenden den ArXiv-Datensatz mit 11 Labels, die die größte Längenvariation bei akademischen Bereichen haben.
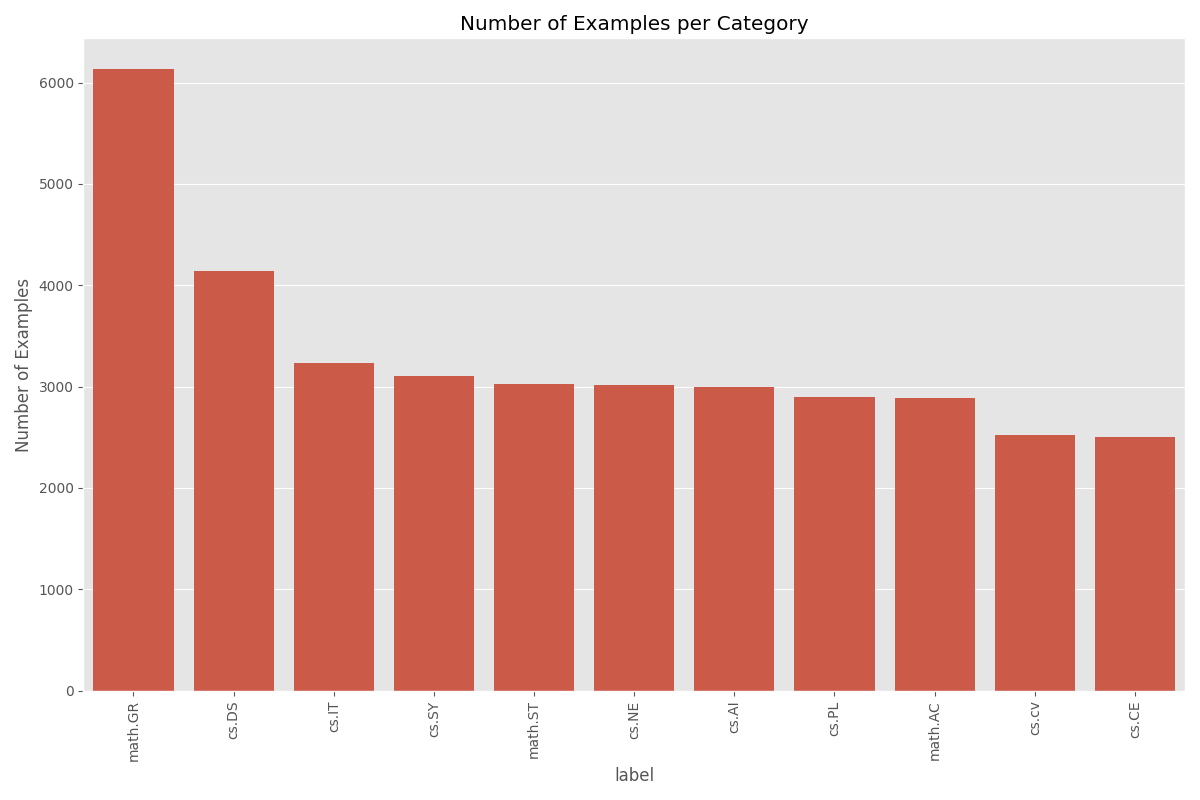
Dokumentenlängen-Kontext: Um diese Wortzählungen besser zu kontextualisieren, können wir sie in Seitenzahlen umwandeln, mit der Standardschätzung von 500 Wörtern pro Seite für doppelt zeilenabstandenen akademischen Text (14.000 Wörter ≈ 28 Seiten ≈ kurze wissenschaftliche Arbeit). Nach diesem Maß:
- math.ST durchschnittlich etwa 28 Seiten
- math.GR und cs.DS sind etwa 25-26 Seiten
- cs.IT und math.AC durchschnittlich etwa 20-24 Seiten
- während cs.CV und cs.NE nur 14-15 Seiten durchschnittlich haben
Diese erhebliche Variation zeigt Unterschiede in Schreibstilen, Dokumententiefe oder Forschungsberichtsnormen bei verschiedenen Fachbereichen. Bereiche wie Mathematik und theoretische Informatik tendieren dazu, umfassendere oder technisch dichtere Dokumente zu produzieren, während angewandte Bereiche wie Computer Vision prägnantere Kommunikation bevorzugen mögen.
3.2.2 Datengröße und Training/Test-Aufteilung
Erwartete Trainingszeit auf Standard-Hardware: 30 Minuten bis 8 Stunden, abhängig von der Methodenkomplexität.
Mindest-Trainingsdatenanforderungen:
- Einfache Methoden: 50+ Beispiele pro Klasse
- Logistic Regression: 100+ Beispiele pro Klasse
- XGBoost: 1.000+ Beispiele für optimale Leistung
- BERT/Transformer-Modelle: 2.000+ Beispiele pro Klasse
In allen Experimenten wurden 30% der Daten als Testset reserviert. Um die Robustheit des Modells zu evaluieren, wurden mehrere Variationen des Datensatzes verwendet: die ursprünglichen klassenverteilten Daten, ein ausgewogener Datensatz basierend auf der minimalen Klassengröße (~2.505 Beispiele) und zusätzliche ausgewogene Datensätze mit festen Größen von 100, 140 und 1.000 Beispielen pro Klasse.
4. Ergebnisse und Analyse
Unsere Experimente zeigen überraschende Ergebnisse zu den Leistungs-Effizienz-Kompromissen bei der Klassifikation langer Dokumente.
Warum traditionelles ML Transformer übertrifft
Unser Benchmark zeigt, dass traditionelle maschinelle Lernansätze mehrere Vorteile bieten:
- Rechnerische Effizienz: Verarbeitung ganzer Dokumente ohne Token-Limits
- Trainingsgeschwindigkeit: 10x schnellere Trainingszeiten bei vergleichbarer Genauigkeit
- Ressourcenanforderungen: Funktionieren effektiv auf Standard-CPU-Hardware
- Skalierbarkeit: Verarbeitung großer Dokumentensammlungen ohne GPU-Infrastruktur
4.1 Leistungs-Rankings
Die vergleichende Evaluation bei vier Datensätzen – Original, Balanced-2505, Balanced-140 und Balanced-100 – zeigt klare Leistungshierarchien:
Top-Performer nach F1-Wert:
XGBoost erreichte die höchsten F1-Werte bei drei Datensätzen:
- Original: F1 = 86
- Balanced-2505: F1 = 85
- Balanced-100: F1 = 75
BERT-base war der Top-Performer beim Balanced-140 Datensatz:
- Balanced-140: F1 = 82 (vs. XGBoost: 81)
Logistic Regression und SVM lieferten ebenfalls konkurrenzfähige Ergebnisse:
- F1-Bereich: 71–83
DistilBERT-base hielt anständige Leistung bei allen Settings:
- F1 ≈ 75–77
RoBERTa-base lieferte konstant schlechte Leistung:
- F1 so niedrig wie 57, besonders in datenarmen Umgebungen
Keyword-basierte Methoden hatten die niedrigsten F1-Werte (53–62)
Fazit: Obwohl XGBoost generell bei den meisten Datensatz-Szenarien am besten performt, übertrifft BERT-base es leicht bei mittelgroßen Datensätzen wie Balanced-140. Dies deutet darauf hin, dass Transformer-Modelle traditionelle maschinelle Lernmethoden übertreffen können, wenn eine moderate Menge an Daten und ausreichende GPU-Ressourcen verfügbar sind. Allerdings ist der Leistungsunterschied nicht signifikant, und XGBoost bleibt die ausgewogenste Option, die hohe Genauigkeit, Robustheit und rechnerische Effizienz bei verschiedenen Datensatzgrößen bietet.
4.2 Kosten-Nutzen-Analyse jeder Methode
Eine eingehende Analyse der Trainings- und Inferenzzeiten zeigt eine große Kluft in den Ressourcenanforderungen zwischen traditionellen ML-Methoden und transformer-basierten Modellen:
Trainings- und Inferenzzeiten:
Effizienteste
- Logistic Regression:
- Training: 2–19 Sekunden bei allen Datensätzen
- Inferenz: ~0.01–0.06 Sekunden
- Ressourcenverbrauch: Minimal CPU & RAM (~50MB)
- Am besten geeignet für schnelle Bereitstellung und ressourcenbeschränkte Umgebungen.
- XGBoost:
- Training: Reicht von 23s (Balanced-100) bis 369s (Balanced-2505)
- Inferenz: ~0.00–0.09 Sekunden
- Ressourcenverbrauch: Effizient auf CPU (~100MB RAM)
- Exzellenter Kompromiss zwischen Geschwindigkeit und Genauigkeit, besonders für große Datensätze.
Ressourcenintensiv
- SVM:
- Training: Bis zu 2.480s
- Inferenz: Bis zu 1.322s
- Hohe Komplexität und Laufzeit machen es ungeeignet für Echtzeit oder Produktionsnutzung.
- Transformer-Modelle:
- DistilBERT-base: Training ≈ 900–1.400s; Inferenz ≈ 140s
- BERT-base: Training ≈ 1.300–2.700s; Inferenz ≈ 127–138s
- RoBERTa-base: Schlechteste Leistung und höchste Trainingszeit (bis zu 2.718s)
- GPU-intensiv (≥2GB RAM) und langsame Inferenz machen sie unpraktisch, es sei denn maximale Genauigkeit ist kritisch.
Ineffizient bei der Inferenz
- Keyword-basierte Methoden:
- Training: Sehr schnell (so niedrig wie 3–135s)
- Inferenz: Überraschend langsam — bis zu 335s
- Obwohl einfach zu implementieren, machen die langsame Inferenz und schlechte Genauigkeit sie ungeeignet für großangelegte oder Echtzeit-Nutzung.
Fazit: Traditionelle ML-Methoden wie Logistic Regression und XGBoost bieten die beste Kosteneffizienz für den praktischen Einsatz, mit schnellem Training, nahezu sofortiger Inferenz und hoher Genauigkeit ohne GPU-Abhängigkeit. Transformer-Modelle bieten verbesserte Leistung nur bei bestimmten Datensätzen (z.B. BERT bei Balanced-140), verursachen aber erhebliche Ressourcen- und Zeitkosten, die in vielen Szenarien möglicherweise nicht gerechtfertigt sind. Es ist wichtig zu beachten, dass die Ressourcenanforderungen von Transformer-Modellen exponentiell mit wachsender Komplexität steigen, wie größeren Datenvolumen.
4.3 Vollständige Modellevaluationszusammenfassung
| Datensatz | Methoden | Modell | Accuracy (%) | Precision (%) | Recall (%) | F1-Wert (%) | Trainingszeit (s) | Testzeit (s) |
|---|---|---|---|---|---|---|---|---|
| Original | Einfach | Keyword-basiert | 56 | 57 | 56 | 55 | 135 | 335 |
| Traditionell | Logistic Regression | 84 | 83 | 84 | 83 | 19 | 0.06 | |
| SVM | 84 | 83 | 84 | 83 | 2480 | 1322 | ||
| MLP | 80 | 80 | 80 | 80 | 426 | 0.53 | ||
| XGBoost | 86 | 86 | 86 | 86 | 364 | 0.08 | ||
| Balanced-2505 | Einfach | Keyword-basiert | 53 | 53 | 53 | 53 | 50 | 253 |
| Traditionell | Logistic Regression | 83 | 83 | 83 | 83 | 17 | 0.05 | |
| SVM | 82 | 82 | 82 | 82 | 1681 | 839 | ||
| MLP | 78 | 79 | 78 | 78 | 301 | 0.41 | ||
| XGBoost | 85 | 85 | 85 | 85 | 369 | 0.09 | ||
| Balanced-100 | Einfach | Keyword-basiert | 54 | 56 | 54 | 54 | 3 | 10 |
| Traditionell | Logistic Regression | 72 | 71 | 72 | 71 | 2 | 0.01 | |
| SVM | 72 | 73 | 72 | 72 | 7 | 2 | ||
| MLP | 73 | 73 | 73 | 73 | 15 | 0.02 | ||
| XGBoost | 76 | 76 | 76 | 75 | 23 | 0 | ||
| Transformer-basiert | DistilBERT-base | 75 | 75 | 75 | 75 | 907 | 141 | |
| BERT-base | 77 | 78 | 77 | 77 | 1357 | 127 | ||
| RoBERTa-base | 55 | 62 | 55 | 57 | 1402 | 124 | ||
| Balanced-140 | Einfach | Keyword-basiert | 62 | 63 | 62 | 62 | 3 | 14 |
| Traditionell | Logistic Regression | 79 | 79 | 79 | 79 | 3 | 0.01 | |
| SVM | 78 | 79 | 78 | 78 | 14 | 4 | ||
| MLP | 78 | 79 | 78 | 78 | 19 | 0.02 | ||
| XGBoost | 81 | 80 | 81 | 80 | 34 | 0 | ||
| Transformer-basiert | DistilBERT-base | 77 | 77 | 77 | 77 | 1399 | 142 | |
| BERT-base | 82 | 82 | 82 | 82 | 2685 | 138 | ||
| RoBERTa-base | 64 | 64 | 64 | 64 | 2718 | 139 |
4.4 Modellauswahlentscheidungsmatrix
| Kriterium | Bestes Modell | Anmerkungen |
|---|---|---|
| Höchste Genauigkeit (Alle Daten) | XGBoost | F1 = 86 |
| Höchste Genauigkeit (Klein-Mittlere Daten) – CPU-Zugang | XGBoost | F1 = 81 |
| Höchste Genauigkeit (Klein-Mittlere Daten) – GPU-Zugang | BERT-base | F1 = 82 |
| Schnellstes Modell | Logistic Regression | Training in <20s |
| Beste Effizienz (Geschwindigkeit/Genauigkeits-Kompromiss) | Logistic Regression | Exzellente Balance zwischen Laufzeit, Einfachheit und Genauigkeit |
| Bester Large-Scale-Klassifizierer | XGBoost | Skaliert gut mit großen Datensätzen, robust gegenüber Ungleichgewicht |
| Beste GPU-Nutzung | BERT-base | Hohe Genauigkeit bei verfügbarer GPU; besser als RoBERTa/DistilBERT-base |
| Nicht empfohlen | RoBERTa-base, Keyword-basiert | Schlechte Genauigkeit, lange Inferenzzeiten, kein Leistungsvorteil |
4.5 Robustheitsanalyse
Dieser Abschnitt analysiert die Robustheit verschiedener Modelle bei unterschiedlichen Datensatzgrößen und -bedingungen und hebt ihre Stärken, Limitationen und Bereiche hervor, die weitere Untersuchung benötigen.
Hochkonfidente Erkenntnisse:
- XGBoost zeigt robuste Leistung bei verschiedenen Datensatzgrößen, besonders für große und kleine Datenregimes (Original, Balanced-100).
- BERT-base zeigt starke Leistung bei mittelgroßen Datensätzen (Balanced-140), was darauf hindeutet, dass Transformer-Modelle traditionelles ML unter den richtigen Daten- und Rechenbedingungen übertreffen können.
- Logistic Regression bleibt eine konstant zuverlässige Grundlinie und liefert starke Ergebnisse mit minimalen Rechenkosten.
- Traditionelle ML-Modelle, besonders XGBoost und Logistic Regression, bieten hohe Effizienz mit konkurrenzfähiger Genauigkeit, besonders wenn Rechenressourcen begrenzt sind.
Bereiche, die weitere Forschung erfordern:
- RoBERTa-bases schwache Leistung bei allen Settings ist unerwartet und könnte von aufgabenspezifischen Limitationen oder suboptimalen Feinabstimmungsstrategien herrühren.
- Transformer-Segmentierungsstrategien erfordern weitere Domain-Adaptation – aktuelle Leistung könnte durch generische Aufteilungs- oder Truncation-Techniken begrenzt sein.
Fazit: Während traditionelle ML-Methoden wie XGBoost und Logistic Regression robust sind, können Transformer-Modelle wie BERT-base sie unter spezifischen Bedingungen übertreffen. Diese Ergebnisse unterstreichen die Wichtigkeit, Modellkomplexität an Datenskala und Bereitstellungseinschränkungen anzupassen, anstatt anzunehmen, dass ausgeklügeltere Architekturen standardmäßig bessere Ergebnisse liefern.
5. Bereitstellungs-Szenarien
In diesem Abschnitt erkunden wir Bereitstellungsszenarien für Textklassifikationsmodelle und heben die best-geeigneten Algorithmen für verschiedene operative Einschränkungen hervor – von Produktionssystemen bis hin zu schneller Prototypenerstellung – basierend auf Kompromissen zwischen Genauigkeit, Effizienz und Ressourcenverfügbarkeit.
Produktionssysteme
- Empfehlung: XGBoost
- Begründung: Erreicht den höchsten F1-Wert (86) bei vollständigen Datensätzen mit schneller Inferenz (~0.08s) und moderater Trainingszeit (~6 Minuten).
- Anwendungsfall: High-Volume oder Batch-Processing-Abläufe, wo sowohl Genauigkeit als auch Durchsatz wichtig sind.
- Hinweise: Robust bei Datensatzgrößen; geeignet für Umgebungen mit Standard-CPU-Infrastruktur.
Ressourcenbeschränkte Umgebungen
- Empfehlung: Logistic Regression
- Begründung: Extrem leichtgewichtig (Training <20s, Inferenz ~0.01s), mit konkurrenzfähigen F1-Werten (bis zu 83).
- Anwendungsfall: Edge-Geräte, eingebettete Systeme und Low-Budget-Bereitstellungen.
- Hinweise: Auch ideal für schnelle Erklärbarkeit und Debugging.
Maximale Genauigkeit mit GPU-Zugang
- Empfehlung: BERT-base
- Begründung: Übertrifft XGBoost bei moderat großen Datensätzen (F1 = 82 vs. 80 bei Balanced-140).
- Anwendungsfall: Forschung, Compliance/Rechtsdokumentenklassifikation und Anwendungen, wo marginale Genauigkeitsverbesserungen missionskritisch sind.
- Hinweise: Erfordert GPU-Infrastruktur (~2GB RAM); längere Trainings- und Inferenzzeiten.
Schnelle Prototypenerstellung
- Empfohlene Verarbeitungskette: Logistic Regression → XGBoost → BERT-base
- Begründung: Ermöglicht iterative Verfeinerung – beginnen Sie einfach und skalieren Sie Komplexität nur bei Bedarf.
- Anwendungsfall: Frühe Experimentierungsphase, Kategorientesting oder ressourcenphasierte Projekte.
Nicht empfohlen
- RoBERTa-base: Schlechte F1-Werte (so niedrig wie 57), lange Trainings-/Inferenzzeit, kein Leistungsvorteil.
- Keyword-basierte Methoden: Schnell zu implementieren, aber niedrige Genauigkeit (F1 ≈ 53–62) und überraschend langsame Inferenz.
Fazit: Das beste Modell für die Bereitstellung hängt von Datengröße, Infrastrukturbeschränkungen und Genauigkeitsbedürfnissen ab. XGBoost ist optimal für allgemeine Produktion, Logistic Regression glänzt unter begrenzten Ressourcen, und BERT-base wird bevorzugt, wenn Genauigkeit höchste Priorität hat und GPU-Computing verfügbar ist. Das standardmäßige Setzen auf Komplexität wird nicht empfohlen – empirische Evidenz unterstützt traditionelles ML für viele praktische Anwendungsfälle.
7. Fazit
Diese Benchmark-Studie präsentiert eine umfassende Evaluation traditioneller und moderner Ansätze für die Klassifikation langer Dokumente bei einer Reihe von Datensatzgrößen und Ressourcenbeschränkungen. Entgegen gängigen Annahmen zeigen unsere Erkenntnisse, dass komplexe Transformer-Modelle nicht immer einfachere maschinelle Lernmethoden übertreffen, besonders in praktischen Bereitstellungsbedingungen.
Zusammenfassung der wichtigsten Erkenntnisse
- XGBoost sticht als robusteste und skalierbarste Lösung insgesamt hervor und erreicht den höchsten F1-Wert (86) bei vollständigen Datensätzen mit konstanter Leistung bei verschiedenen Stichprobengrößen. Es bietet exzellente rechnerische Effizienz und eignet sich gut für Produktionsumgebungen, die große Dokumentensammlungen handhaben. Dennoch performt es auch akzeptabel bei kleineren Datensätzen – beispielsweise erreicht es einen F1-Wert von 81 bei Balanced-140.
- BERT-base liefert die höchste Genauigkeit bei mittelgroßen Datensätzen (z.B. F1 = 82 bei Balanced-140) und übertrifft XGBoost in diesem Setting. Allerdings erfordert es GPU-Infrastruktur und verursacht erhebliche Trainings- und Inferenzzeiten, was es ideal für Forschung oder kritische Anwendungen macht, wo Ressourcenverfügbarkeit kein limitierender Faktor ist.
- Logistic Regression bleibt eine herausragende Wahl für ressourcenbeschränkte Umgebungen. Es trainiert in unter 20 Sekunden, inferiert nahezu sofort und erreicht konkurrenzfähige F1-Werte (bis zu 83), was es ideal für schnelle Prototypenerstellung, eingebettete Systeme und Edge-Bereitstellung macht.
- RoBERTa-base lieferte konstant schlechte Leistung, trotz seines Rufs, mit F1-Werten so niedrig wie 57. Dies unterstreicht die Notwendigkeit für empirisches Benchmarking anstatt sich allein auf wahrgenommene Modellstärke zu verlassen.
- Keyword-basierte und ähnlichkeitsbasierte Methoden sind unzureichend für komplexe, Multi-Class-Klassifikation langer Dokumente, trotz ihrer Einfachheit und schnellen Einrichtung. Ihre niedrige Genauigkeit und unerwartet langen Inferenzzeiten machen sie ungeeignet für ernsthafte Bereitstellung.
Strategische Empfehlungen
- Beginnen Sie mit traditionellen ML-Modellen wie Logistic Regression oder XGBoost. Sie bieten starke Leistung mit minimalem Overhead und ermöglichen schnelle Iteration.
- Verwenden Sie BERT-base nur wenn marginale Genauigkeitsverbesserungen missionskritisch sind und GPU-Ressourcen verfügbar sind.
- Vermeiden Sie eine Überkomplikation früher Phasen der Modellauswahl – die Ergebnisse zeigen, dass einfache Modelle oft überraschend konkurrenzfähige Ergebnisse für die Klassifikation langer Texte liefern.
- Passen Sie Ihr Modell sorgfältig an Ihr spezifisches Bereitstellungsszenario an und berücksichtigen Sie die Balance zwischen Genauigkeit, Laufzeit, Speicheranforderungen und Datenverfügbarkeit.
Zukünftige Forschungsrichtungen
Mehrere Bereiche verdienen tiefere Untersuchung:
- Domain-adaptive Feinabstimmungs- und Segmentierungsstrategien für Transformer-Modelle
- Erforschung von Hybrid-Abläufen, die schnelle traditionelle ML-Backends mit transformer-basiertem Reranking oder Verfeinerung kombinieren
- Untersuchung, warum RoBERTa unterperformt und ob aufgabenspezifische Anpassungen sein Potenzial wiederherstellen könnten
- Evaluation von neuen Long-Context-Transformern (z.B. Longformer, BigBird) auf diesem Benchmark
Abschließende Erkenntnis
Dieses Benchmark stellt die Überzeugung in Frage, dass Modellkomplexität immer gerechtfertigt ist. In Wirklichkeit können traditionelle ML-Modelle exzellente Leistung für die Klassifikation langer Dokumente liefern – oft erreichen sie die gleiche oder übertreffen Transformer sowohl in Genauigkeit als auch Geschwindigkeit, mit 10× weniger Rechenkosten.
Der Schlüssel zum Erfolg liegt nicht darin, das mächtigste Modell zu verfolgen, sondern das richtige Modell für Ihre spezifischen Daten, Einschränkungen und Ziele zu wählen.
Quellenverzeichnis
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A., Nunes, C. und Jatowt, A. (2020) ‚YAKE! Keyword Extraction from Single Documents Using Multiple Local Features‘, Information Sciences, 509, S. 257-289.
Chen, T. und Guestrin, C. (2016) ‚XGBoost: A Scalable Tree Boosting System‘, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM.
Devlin, J., Chang, M.-W., Lee, K. und Toutanova, K. (2019) ‚BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding‘, in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Band 1 (Long and Short Papers). Minneapolis: Association for Computational Linguistics.
Genkin, A., Lewis, D. D. und Madigan, D. (2005) Sparse Logistic Regression for Text Categorization. DIMACS Working Group on Monitoring Message Streams Project Report.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. und Stoyanov, V. (2019) ‚RoBERTa: A Robustly Optimized BERT Pretraining Approach‘, arXiv preprint arXiv:1907.11692.
Sanh, V., Debut, L., Chaumond, J. und Wolf, T. (2019) ‚DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter‘, arXiv preprint arXiv:1910.01108.
Download-Ressourcen und Bibliotheken
- Liqun W. (2021). Long Document Dataset — GitHub Repository
- S2ORC (Semantic Scholar Open Research Corpus)
- Congressional and California state bills — GitHub Repository
- GOVREPORT – long document summarization dataset
- CUAD (Contract Understanding Atticus Dataset)
- MIMIC-III (Medical Information Mart for Intensive Care)
- SEC 10 K/Q Filings
- scikit-learn 1.3.0
- transformers 4.38.0
- torch 2.7.1
- xgboost 3.0.2
- Alle Code und Konfigurationen im Zusammenhang mit der Klassifikation langer Dokumente Benchmark 2025 — GitHub Repository