Executive Summary
Die ESG-Datenerfassung steht vor einem Paradigmenwechsel: Mit der Corporate Sustainability Reporting Directive (CSRD) werden EU-weit zahlreiche Unternehmen detaillierte Nachhaltigkeitsdaten erfassen – eine massive Ausweitung bisheriger Anforderungen. Manuelle Excel-Prozesse stoßen an ihre Grenzen, während KI-gestützte Plattformen die Erfassung durch automatisierte Datenextraktion, intelligente Validierung und Cloud-basierte Integration revolutionieren. Erfolgreiche Implementierung erfordert einen strukturierten Ansatz mit klarem Change Management. Unternehmen, die ESG-Datenerfassung strategisch angehen, wandeln regulatorische Pflicht in Wettbewerbsvorteil um.
Inhaltsverzeichnis
- Die Herausforderung: Warum ESG-Datenerfassung so komplex ist
- Technologische Lösungen: KI als Gamechanger
- Die 6-Layer ESG-Datenarchitektur
- Best Practices der Implementierung
- Ausblick: Die Zukunft der ESG-Datenerfassung
- Fazit: Von der Pflicht zum Wettbewerbsvorteil
Die Herausforderung: Fragmentierte Daten in einer komplexen Regulierungslandschaft
Das neue regulatorische Umfeld
Die Corporate Sustainability Reporting Directive (CSRD) der Europäischen Union markiert einen Wendepunkt in der Nachhaltigkeitsberichterstattung. Ab 2024 werden schrittweise mehr Unternehmen in der EU zur detaillierten Nachhaltigkeitsberichterstattung verpflichtet – eine erhebliche Ausweitung gegenüber bisherigen Anforderungen. Eine Analyse von PwC zeigt, dass sich die Zahl der berichtspflichtigen Unternehmen durch die CSRD von bisher rund 11.600 auf etwa 49.000 erhöht (PwC, 2023).
Die European Sustainability Reporting Standards (ESRS) bilden den inhaltlichen Rahmen der Berichterstattung. Sie definieren mehrere hundert qualitative und quantitative Datenpunkte, die Unternehmen systematisch erfassen müssen. Obwohl der endgültige Umfang einiger Details erst durch begleitende Rechtsakte und den Umsetzungsstand in den Mitgliedstaaten konkretisiert wird, ist klar, dass die Anforderungen umfassender und datenintensiver ausfallen als unter der bisherigen NFRD.
Der Preis manueller Prozesse
Trotz fortschreitender Digitalisierung verlassen sich viele Organisationen bei der ESG-Datenerfassung weiterhin auf manuelle, tabellenbasierte Prozesse. Befragungen zeigen, dass Unternehmen genau hier an Grenzen stoßen: Laut PwC berichten 55 % der Unternehmen, dass Datenqualitätsprobleme zu den größten Herausforderungen im CSRD-Reporting gehören (PwC, 2024a).
Die Konsequenzen manueller Prozesse sind erheblich: hoher Zeitaufwand, Fehleranfälligkeit, fehlende Nachvollziehbarkeit und Schwierigkeiten bei der prüfungssicheren Dokumentation. Die PwC-Ergebnisse belegen, dass Unternehmen zunehmend technologische Lösungen als notwendig ansehen, um die steigenden Anforderungen zu erfüllen und die Qualität der Nachhaltigkeitsdaten sicherzustellen (PwC, 2024a).
Die Fragmentierung der Datenlandschaft
Eine zusätzliche Studie zeigt, dass bereits heute viele Unternehmen mit unvollständigen und verteilten ESG-Daten kämpfen: Rund zwei Drittel der deutschen Unternehmen haben ihre Gap-Analyse zur CSRD-Erfüllung begonnen, stoßen jedoch vor allem auf Herausforderungen bei Datenverfügbarkeit und -integration (PwC, 2024b).
Dies deckt sich mit der praktischen Erfahrung vieler Organisationen: ESG-relevante Daten stammen aus unterschiedlichen Systemen – ERP, HR, Facility-Management, Produktionsanlagen oder Lieferkettentools – und liegen oft in verschiedenen Formaten vor. Die Fragmentierung erhöht den Aufwand und erschwert die Berichtsqualität, weshalb Unternehmen verstärkt zentrale Datenplattformen und API-basierte Integrationen nutzen.
Technologische Lösungen: KI als Gamechanger
Der technologische Reifegrad
Künstliche Intelligenz und Automatisierung bieten fundamentale Lösungen für die ESG-Datenerfassung. Die Technologie hat einen Reifegrad erreicht, der weit über einfache Digitalisierung hinausgeht. Moderne KI-Systeme erfassen nicht nur Daten, sondern verstehen Zusammenhänge, identifizieren Anomalien und lernen kontinuierlich aus Mustern. Der Markt für ESG-Software entwickelt sich dynamisch, mit einer wachsenden Zahl spezialisierter Anbieter, die KI-gestützte Lösungen entwickeln.
Automatisierte Datenerfassung: Von der Quelle zum Dashboard
Der erste und zeitintensivste Schritt im ESG-Reporting ist die Datenerfassung selbst. Energieverbrauchsdaten müssen aus Zählerständen und Rechnungen extrahiert werden. Wasserverbrauch, Abfallmengen, Transportkilometer – all diese Datenpunkte liegen oft in unstrukturierten Formaten vor: PDF-Rechnungen, gescannte Dokumente, E-Mail-Anhänge.
API-Integrationen ermöglichen direkte Anbindungen an Energieversorger, Tankkarten-Anbieter oder IoT-Sensoren für Echtzeit-Datenströme. Moderne Machine-Learning-Modelle und Frameworks wie Docling erkennen nicht nur Text, sondern verstehen die Struktur von Dokumenten, identifizieren relevante Datenfelder auch bei variierenden Layouts und ordnen extrahierte Werte automatisch den richtigen Kategorien zu. Einen aktuellen Vergleich verschiedener Frameworks gibt es hier: PDF-Datenextraktion Benchmark 2025: Vergleich von Docling, Unstructured und LlamaParse für Dokumentenverarbeitungsprozesse.
In der Praxis bedeutet dies: Energierechnungen von dutzenden Standorten werden automatisch eingelesen, Verbrauchswerte extrahiert, nach Energieträgern kategorisiert und in standardisierte Einheiten umgerechnet. Was früher Tage manueller Arbeit erforderte, geschieht in Minuten – ohne die typischen Tippfehler menschlicher Dateneingabe. Ein konkretes Beispiel liefert die KION Group, die durch Automatisierung der Kraftstoffverbrauchserfassung eine Zeitersparnis von 85% und eine Datenqualität von 99,5% erreichen konnte (Javanmard, 2025).
Intelligente Datenkonsolidierung und Validierung
Nach der Erfassung folgt die Konsolidierung: Daten aus unterschiedlichen Systemen müssen harmonisiert, auf Konsistenz geprüft und aggregiert werden. Machine-Learning-Algorithmen erkennen Muster und Zusammenhänge zwischen verschiedenen Datenquellen, identifizieren Duplikate automatisch und harmonisieren Datenformate. Wenn ein Standort Energieverbrauch in Kilowattstunden meldet, ein anderer in Megajoule und ein dritter in britischen Wärmeeinheiten (BTU), konvertiert das System automatisch in eine einheitliche Zieleinheit – eine essenzielle Voraussetzung für die standardisierte Berichterstattung.
Besonders wertvoll ist die automatisierte Plausibilitätsprüfung. KI-Systeme lernen typische Verbrauchsmuster und schlagen Alarm bei Anomalien: Wenn ein Standort plötzlich doppelten Energieverbrauch meldet, wird dies automatisch zur Überprüfung markiert. Zeitreihenanalysen erkennen ungewöhnliche Trends, Ausreißer-Erkennung identifiziert statistische Anomalien, und Cross-Validierung gleicht Daten aus verschiedenen Quellen ab. Diese automatisierten Validierungsmechanismen erhöhen nicht nur die Datenqualität, sondern erfüllen auch die strengen Anforderungen an Nachvollziehbarkeit und Prüfbarkeit, die die CSRD vorschreibt (Europäische Kommission, 2022).
Predictive Analytics und Forecasting
Fortgeschrittene KI-Systeme gehen über reine Datenerfassung hinaus und bieten vorausschauende Analysen. Basierend auf historischen Daten und externen Faktoren können sie zukünftige ESG-Kennzahlen prognostizieren, steigende CO2-Preise besser navigieren, Risiken antizipieren und Optimierungspotenziale aufzeigen. Diese Fähigkeiten verwandeln ESG-Reporting von einer rückwärtsgerichteten Compliance-Übung in ein strategisches Steuerungsinstrument, das Unternehmen dabei unterstützt, die geforderten Nachhaltigkeitsziele proaktiv zu erreichen.
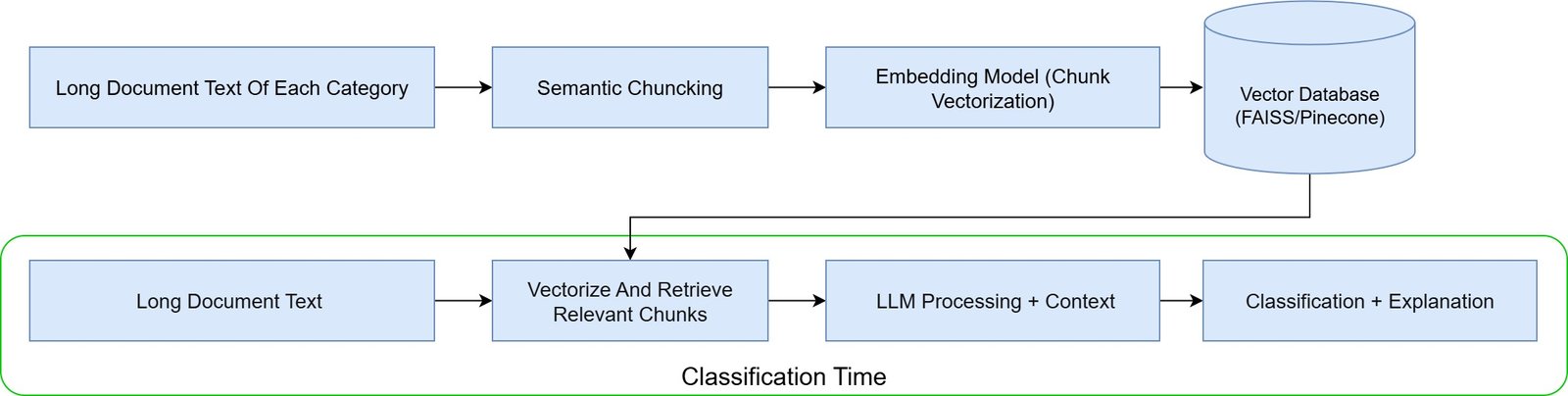
Die 6-Layer ESG 4.0 Architektur: Vom Datenchaos zur Compliance
Die Komplexität der ESG-Datenerfassung erfordert einen systematischen Architekturansatz. Die folgende 6-Layer-Struktur zeigt, wie führende Unternehmen ihre ESG-Datenprozesse organisieren können – von der operativen Datenquelle bis zum fertigen Stakeholder-Report:
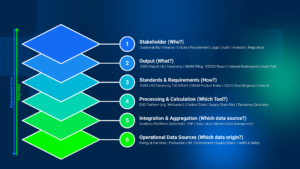
Die sechs Ebenen im Detail:
- Layer 6 – Operational Data Sources (Datenursprung)
An der Basis stehen die operativen Datenquellen, die die Rohdaten liefern:
Energy & Facilities: Energieverbrauchsdaten aus Gebäudemanagementsystemen
Production: Produktionsdaten, Maschinenauslastung, Ausschuss
HR: Mitarbeiterdaten, Diversitätskennzahlen, Weiterbildung
Environment: Emissionsmessungen, Abfallmanagement, Wasserverbrauch
Supply Chain: Lieferantendaten, Transportemissionen
Health & Safety: Arbeitsunfälle, Sicherheitstrainings
Praxisherausforderung: Diese Daten liegen in unterschiedlichen Formaten vor – von IoT-Sensoren über ERP-Systeme bis zu manuellen Excel-Listen.
- Layer 5 – Integration & Aggregation (Datenquelle)
Hier werden die fragmentierten Daten konsolidiert:
Analytics Platform (Data Hub): Zentrale Datendrehscheibe
ERP-Integration: Anbindung an SAP, Oracle, Microsoft Dynamics
Data Lakes: Speicherung strukturierter und unstrukturierter Rohdaten
Master Data Management: Einheitliche Stammdatenstrukturen für Standorte, Organisationseinheiten, Emissionsfaktoren
Technologischer Enabler: Cloud-basierte Integrationsplattformen mit ETL-Pipelines ermöglichen automatisierte Datenflüsse in Echtzeit.
- Layer 4 – Processing & Calculation (Werkzeug)
Die eigentliche Verarbeitungslogik transformiert Rohdaten in berichtsfähige Kennzahlen:
ESG Platform: Spezialisierte Software für ESG-Berechnungen
Carbon Tools: GHG-Protocol-konforme CO2-Berechnung
Supply Chain Risk Tools: Bewertung von Lieferantenrisiken
Taxonomy Calculator: Automatische EU-Taxonomie-Klassifizierung
KI-Einsatz: Machine Learning optimiert Emissionsfaktoren, identifiziert Ausreißer und schließt Datenlücken durch intelligente Imputierung.
- Layer 3 – Standards & Requirements (Regelwerk)
Diese Ebene definiert die Compliance-Anforderungen:
ESRS: European Sustainability Reporting Standards unter der CSRD
EU Taxonomy TSC/DNSH: Technical Screening Criteria und Do No Significant Harm-Prinzipien
CBAM Product Rules: Carbon Border Adjustment Mechanism-Vorgaben
CSDDD Due Diligence: Lieferkettensorgfaltspflichten
Internal Standards: Unternehmenseigene KPIs und Ziele
Dynamische Herausforderung: Diese Regelwerke entwickeln sich kontinuierlich weiter – Systeme müssen regelmäßig aktualisiert werden.
- Layer 2 – Output (Berichtsformat)
Aus den verarbeiteten Daten entstehen verschiedene Outputs:
CSRD Report: Nachhaltigkeitserklärung nach EU-Standard
EU-Taxonomy Reporting: Taxonomie-konforme Offenlegung
CBAM Filing: Grenzausgleichsmechanismus-Meldungen
CSDDD Report: Sorgfaltspflichtenberichte
Internal Dashboards: Management-Cockpits mit Echtzeit-KPIs
Audit Trail: Vollständige Dokumentation für Wirtschaftsprüfer
Best Practice: Template-basierte Berichterstellung mit XBRL-Tagging für digitale Einreichungen.
- Layer 1 – Stakeholder (Zielgruppe)
Die oberste Ebene adressiert die verschiedenen Berichtsempfänger:
Sustainability & Finance: Interne Steuerung und Strategieentwicklung
C-Suite: Vorstandsberichterstattung
Procurement & Legal: Lieferantenmanagement und Compliance
Audit: Wirtschaftsprüfer und interne Revision
Investors & Regulators: Kapitalgeber und Aufsichtsbehörden
Erfolgsfaktor: Stakeholder-spezifische Aufbereitung derselben Datengrundlage – von hochaggregiert für den Vorstand bis granular für Auditoren.
Die beschriebene Architektur mag theoretisch wirken, doch sie bildet die Realität erfolgreicher ESG-Implementierungen ab. Viele Unternehmen, die als Vorreiter im ESG-Bereich gelten, implementieren diese Layer-Struktur bereits erfolgreich in ihre Strategie, u.a. die KION Group (siehe Case Study).
Best Practices der Implementierung
Schritt 1: Stakeholder-Alignment und Zielsetzung
Erfolgreiche ESG-Automatisierung beginnt nicht mit Technologie, sondern mit klarer strategischer Ausrichtung. Definieren Sie zunächst, welche Reporting-Anforderungen erfüllt werden müssen: CSRD, EU-Taxonomie, ESG-Ratings und weitere Rahmenwerke. Identifizieren Sie alle relevanten Stakeholder – von der Nachhaltigkeitsabteilung über IT und Controlling bis zu operativen Einheiten – und klären Sie deren Anforderungen. Legen Sie messbare Ziele fest: Reduzierung des manuellen Aufwands, Verbesserung der Datenqualität, Beschleunigung der Reporting-Zyklen.
Schritt 2: Daten-Inventur und Gap-Analyse
Bevor Sie automatisieren können, müssen Sie verstehen, welche Daten wo vorhanden sind. Führen Sie eine umfassende Bestandsaufnahme durch: Welche ESG-Datenpunkte werden bereits erfasst? In welchen Systemen liegen sie? In welcher Qualität und Granularität? Wo bestehen Lücken? Diese Gap-Analyse zeigt, welche neuen Datenquellen erschlossen werden müssen und wo die Datenqualität verbessert werden muss.
Schritt 3: Pilotierung und iteratives Vorgehen
Starten Sie nicht mit einer riesigen Implementierungsoffensive über alle Standorte und Datenpunkte hinweg. Wählen Sie stattdessen einen überschaubaren Pilotbereich: beispielsweise Energiedaten von fünf Standorten oder eine spezifische Kategorie wie Scope-1-Emissionen. Testen Sie Technologie und Prozesse im kleinen Maßstab, lernen Sie schnell aus Herausforderungen und skalieren Sie schrittweise. Dieser iterative Ansatz minimiert Risiken, ermöglicht kontinuierliche Verbesserung und schafft ein Momentum, das alle Stakeholder mitzieht.
Schritt 4: Change Management und Training
Technologie allein garantiert keinen Erfolg. Mitarbeiter müssen neue Systeme verstehen, akzeptieren und korrekt nutzen. Investieren Sie in umfassendes Training, kommunizieren Sie den Mehrwert der Automatisierung klar, adressieren Sie Bedenken proaktiv und binden Sie alle Mitarbeiter ein. Benennen Sie ESG-Data-Champions in verschiedenen Abteilungen, die als Multiplikatoren fungieren und lokale Unterstützung bieten.
Schritt 5: Kontinuierliche Optimierung
ESG-Datenerfassung ist kein einmaliges Projekt, sondern ein kontinuierlicher Prozess. Regulatorische Anforderungen entwickeln sich weiter, neue Datenquellen werden verfügbar und Technologie verbessert sich. Etablieren Sie Mechanismen für regelmäßige Reviews: Werden die gesetzten Ziele erreicht? Wo bestehen Optimierungspotenziale? Wie entwickeln sich Best Practices in der Branche? Nutzen Sie diese Erkenntnisse für die kontinuierliche Verbesserung.
Ausblick: Die Zukunft der ESG-Datenerfassung
Echtzeit-ESG-Monitoring
Die Zukunft gehört dem Echtzeit-Monitoring von ESG-Kennzahlen. Während heute die meisten Unternehmen quartalsweise oder jährlich berichten, ermöglichen IoT-Sensoren, Smart Meters und direkte Systemintegrationen künftig die kontinuierliche Überwachung. Energieverbrauch, Wassernutzung oder Produktionsemissionen werden in Echtzeit erfasst, analysiert und visualisiert. Dies erlaubt nicht nur schnellere Entscheidungen, sondern auch proaktives Management: Anomalien werden sofort erkannt, Gegenmaßnahmen können unmittelbar eingeleitet werden.
Blockchain für Transparenz und Vertrauen
Blockchain-Technologie verspricht unveränderbare, transparente Aufzeichnungen von ESG-Daten entlang komplexer Lieferketten. Ein Produkt könnte seinen vollständigen ESG-Fußabdruck vom Rohstoff bis zum Endkunden dokumentieren, wobei jeder Schritt kryptographisch gesichert ist. Dies adressiert ein zentrales Problem der Scope-3-Berichterstattung: die Verifizierung von Lieferantendaten. Obwohl die Technologie noch am Anfang steht, könnten Blockchain-basierte ESG-Datenmanagementsysteme künftig zum Standard werden.
Standardisierung und Interoperabilität
Mit zunehmender Reife des ESG-Reporting-Ökosystems werden Standards für den Datenaustausch und die Interoperabilität entstehen. Initiativen wie das Value Reporting Foundation’s Digital Reporting Project oder die Global Reporting Initiative’s digitale Taxonomien arbeiten an maschinenlesbaren Standards. Künftig werden ESG-Daten so standardisiert ausgetauscht werden wie heute Finanzdaten via XBRL – was Doppelerfassungen eliminiert und die Vergleichbarkeit erhöht.
Fazit: Von der Pflicht zum Wettbewerbsvorteil
Die CSRD und andere regulatorische Entwicklungen haben das ESG-Reporting von einer freiwilligen Best Practice zu einer verbindlichen Anforderung gemacht (Europäische Kommission, 2022). Unternehmen stehen vor der Wahl: diese Anforderungen als lästige Compliance-Last zu behandeln oder als Chance zur strategischen Transformation zu begreifen.
Die intelligente Automatisierung der ESG-Datenerfassung ist der Schlüssel zu dieser Transformation. Sie reduziert nicht nur Aufwand und Fehler, sondern schafft die Datenbasis für fundierte Nachhaltigkeitsentscheidungen, die sich ökonomisch lohnen können. Unternehmen mit robusten ESG-Dateninfrastrukturen können schneller auf regulatorische Änderungen reagieren, Risiken frühzeitig erkennen, Effizienzpotenziale identifizieren und ihre Nachhaltigkeitsleistung glaubwürdig kommunizieren.
Der Weg zur automatisierten ESG-Datenerfassung erfordert strategische Planung, technologische Investitionen und einen organisatorischen Wandel. Aber die Investition zahlt sich mehrfach aus: durch Effizienzgewinne, bessere Entscheidungsgrundlagen, geringere Compliance-Risiken und nicht zuletzt durch verbesserten Zugang zu nachhaltigkeitsorientiertem Kapital. In einer Welt, in der Nachhaltigkeit zunehmend zum entscheidenden Wettbewerbsfaktor wird, sind automatisierte ESG-Datenerfassungssysteme nicht mehr optional – sie sind essenziell für den langfristigen Unternehmenserfolg.
Häufig gestellte Fragen zur automatisierten ESG-Datenerfassung
Was ist ESG-Datenerfassung?
Welche Datenpunkte müssen unter der CSRD erfasst werden?
Die CSRD mit den European Sustainability Reporting Standards (ESRS) erfordert die Erfassung von mehreren hundert Datenpunkten. Diese umfassen:
- Umweltdaten: Treibhausgasemissionen (Scope 1, 2, 3), Energieverbrauch, Wassernutzung, Abfallmengen
- Sozialdaten: Diversitätskennzahlen, Arbeitssicherheit, Weiterbildungsmaßnahmen, Arbeitsbedingungen in der Lieferkette
- Governance-Daten: Vorstandsstrukturen, Compliance-Kennzahlen, Antikorruptionsmaßnahmen
- Wertschöpfungskettendaten: Informationen von Lieferanten und Kunden
Wie kann KI die ESG-Datenerfassung verbessern?
Künstliche Intelligenz revolutioniert die ESG-Datenerfassung durch:
- Automatisierung: KI-gestützte Systeme extrahieren Daten automatisch aus verschiedenen Quellen wie E-Mails, PDFs und Rechnungen
- Validierung: Machine Learning erkennt Anomalien und Inkonsistenzen in Echtzeit
- Predictive Analytics: Vorhersage von Datentrends und frühzeitige Identifikation von Risiken
- Natural Language Processing: Verarbeitung unstrukturierter Textdaten aus Berichten und Dokumenten
- Effizienzsteigerung: Reduzierung manueller Aufwände um bis zu 70%
Was sind die größten Herausforderungen bei der ESG-Datenerfassung?
Die größten Herausforderungen bei der ESG-Datenerfassung sind:
- Datensilos: Informationen sind über verschiedene Abteilungen und Systeme verteilt
- Manuelle Prozesse: Zeitaufwändige Excel-basierte Erfassung mit hoher Fehleranfälligkeit
- Scope 3 Emissionen: Erfassung von Lieferkettendaten, die oft 70-90% der Gesamtemissionen ausmachen
- Datenqualität: Sicherstellung von Vollständigkeit, Genauigkeit, Konsistenz und Aktualität
- Fehlende Standardisierung: Unterschiedliche Frameworks und Berichtsanforderungen
Welche technischen Anforderungen sind für eine erfolgreiche ESG-Datenerfassung notwendig?
Für eine erfolgreiche ESG-Datenerfassung sind folgende technische Komponenten erforderlich:
- Zentrale Datenplattform: Cloud-basierte Lösung zur Konsolidierung aller ESG-Daten
- API-Schnittstellen: Anbindung an bestehende ERP-, HR- und Finanzsysteme
- Automatisierungsfunktionen: KI-gestützte Datenextraktion und -validierung
- Workflow-Management: Steuerung von Genehmigungsprozessen und Datenfreigaben
- Audit Trail: Lückenlose Dokumentation aller Datenänderungen für Compliance
- Reporting-Engine: Flexible Berichterstellung nach verschiedenen Standards (CSRD, GRI, TCFD)
Quellenverzeichnis
Europäische Kommission (2022) Corporate Sustainability Reporting Directive (CSRD). Brüssel: Europäische Kommission. Verfügbar unter: https://finance.ec.europa.eu/capital-markets-union-and-financial-markets/company-reporting-and-auditing/company-reporting/corporate-sustainability-reporting_en
Javanmard, A. (2025) Kraftstoffverbrauchserfassung: Wie KION 85% Zeitersparnis und 99,5% Datenqualität im ESG Reporting erreichte. Procycons. Verfügbar unter: https://procycons.com/de/blogs/case-study/kraftstoffverbrauchserfassung/
PwC (2023) Corporate Sustainability Reporting Directive (CSRD) 2023 – An analysis. Zürich: PwC Schweiz. Verfügbar unter: https://www.pwc.ch/en/publications/2023/Study_CSRD_ENG_20231121.pdf
PwC (2024a) 55% of companies cite data quality challenges in CSRD reporting. PwC Luxemburg. Verfügbar unter: https://www.pwc.lu/en/press/press-releases-2024/data-quality-challenges-csrd-reporting.html
PwC (2024b) Global CSRD Survey 2024 – Ergebnisse für Deutschland. PwC Deutschland. Verfügbar unter: https://www.pwc.de/de/nachhaltigkeit/global-csrd-survey-2024-ergebnisse-fuer-deutschland.html