In einer Welt, in der Künstliche Intelligenz (KI) zunehmend unser Online-Erlebnis prägt, entsteht eine neue Disziplin im digitalen Marketing: „Generative Engine Optimization“ (kurz: GEO). Zwar spielt die klassische Suchmaschinenoptimierung (SEO) weiterhin eine zentrale Rolle bei der Suche nach digitalen Inhalten, doch gleichzeitig verändert der rasante Aufstieg KI-basierter Suchsysteme und Chatbots wie ChatGPT, Perplexity oder Gemini die Art und Weise, wie Menschen im Internet nach Informationen suchen – und wie Inhalte gefunden werden.
Bei GEO handelt es sich um eine Content-Strategie, die darauf abzielt, Inhalte so zu gestalten und zu strukturieren, dass sie von generativen KI-Systemen optimal verarbeitet, verstanden und bevorzugt angezeigt werden können. GEO erweitert damit die klassische SEO um gezielte Maßnahmen, die auf generative Suchergebnisse ausgelegt sind – mit dem Ziel, die Sichtbarkeit von Marken und Inhalten in KI-gestützten Antworten deutlich zu erhöhen.
Die Disziplin wird unter verschiedenen Begriffen geführt, darunter LLMO (Large Language Model Optimization), AIO (AI Optimization), GAIO (Generative AI Optimization) oder AEO (Answer Engine Optimization). Trotz der unterschiedlichen Bezeichnungen verfolgen sie alle ein gemeinsames Ziel: Inhalte so zu optimieren, dass sie in einer von KI geprägten Suche die höchste Relevanz, Sichtbarkeit und Autoritätentfalten können.
Mit dem Aufkommen leistungsstarker Sprachmodelle und der veränderten Informationssuche durch Nutzer entwickelt sich GEO zunehmend zu einem entscheidenden Erfolgsfaktor im digitalen Marketing. Die Studie “GEO: Generative Engine Optimization” von Aggarwal et al. (2024) liefert hierzu wichtige Grundlagen, da sie systematisch untersucht, welche Inhalte in generativen KI-Antworten besonders gut angenommen werden.
Wieso ist GEO wichtig?
Die digitale Suche steht aktuell vor einem grundlegenden Wandel: Laut Gartner wird das Suchvolumen über klassische Suchmaschinen bis 2026 um 25 % zurückgehen – vor allem aufgrund des Aufstiegs von KI-Chatbots und virtuellen Assistenten (Gartner, 2024). Schon heute nutzen eine Milliarde Menschen weltweit KI-Chatbots (Anthony Cardillo, 2025), und allein OpenAI verzeichnet mit ChatGPT über 400 Millionen aktive Nutzer pro Woche (Reuters, 2025). Diese Entwicklung zeigt klar: Wer seine Inhalte für generative KI optimiert, sichert sich entscheidende Vorteile in Bezug auf Reichweite, Sichtbarkeit und Markenpositionierung.
Um langfristig relevant zu bleiben, wird es also immer wichtiger, Inhalte gezielt für KI-Plattformen zu optimieren. GEO bietet dabei entscheidende Vorteile für Marken und Content-Ersteller:
Größere Reichweite
Durch die Optimierung für generative KI wird die Sichtbarkeit über klassische Suchmaschinen hinaus deutlich erhöht. Da immer mehr Nutzer auf KI-Plattformen setzen, erreicht GEO-optimierter Content eine neue, erweiterte Zielgruppe.
Verbesserte Nutzererfahrung
GEO sorgt dafür, dass Inhalte von KI-Systemen schneller, relevanter und persönlicher ausgespielt werden. Dadurch steigt die Zufriedenheit und Bindung der Nutzer, da ihre Bedürfnisse präziser erkannt und adressiert werden.
Wettbewerbsvorteil
Wer früh auf GEO setzt, positioniert seine Marke als innovativen Vorreiter im digitalen Wandel. Das schafft Vertrauen, hebt das Unternehmen von der Konkurrenz ab und stärkt die eigene Autorität in einem sich schnell entwickelnden Markt.
Worin unterscheiden sich SEO und GEO?
Während SEO und GEO beide darauf abzielen, die Online-Sichtbarkeit zu erhöhen, gibt es Unterschiede in den gewählten Ansätzen und Zielen:
SEO
GEO
Definition
Eine Strategie, die die Inhalte von Websites so optimiert, dass sie in den traditionellen Suchmaschinenergebnisseiten (Search Engine Result Pages, SERPs) besser platziert werden.
Eine Strategie, die Inhalte für die Sichtbarkeit in Antworten optimiert, die von KI-gesteuerten Suchmaschinen automatisch erstellt werden.
Suchverhalten des Nutzers
Der Nutzer initiiert eigenständig die Suche nach spezifischen Informationen.
Die KI generiert eigenständig Antworten auf Grundlage bereits verfügbarer Daten.
Hauptakteure/Plattformen
Google, Bing, Yahoo, DuckDuckGo
ChatGPT, Perplexity, Gemini, Claude
Ziel
Verbesserung des organischen Rankings auf klassischen Suchmaschinen.
Maximale Sichtbarkeit und Autorität innerhalb von KI-generierten Antworten und Inhalten – inklusive Häufigkeit der Erwähnung und bevorzugter Positionierung am Anfang der Antwort.
Messbarkeit
Sichtbarkeit und Ranking-Positionen in den SERPs, Keyword Performance, organischer Traffic, Klickrate (CTR).
Sichtbarkeit und Autorität in KI-generierten Antworten – inklusive Häufigkeit der Erwähnung und Position innerhalb der Antwort, Referral-Traffic, Klickrate (CTR).
Wie setze ich GEO erfolgreich um?
Eine Analyse verschiedener Vorgehensweisen hat gezeigt, welche Maßnahmen besonders wirksam sind. Getestet wurden unter anderem:
Keyword-Optimierung: Relevante Keywords gezielt und passend im Inhalt integrieren.
Aussagekräftige Begriffe verwenden: Spezifisches und präzises Vokabular einsetzen, um Inhalte anzureichern.
Sprache vereinfachen: Komplexe Sachverhalte klar und verständlich darstellen.
Autoritativer Schreibstil: Überzeugende, selbstbewusste Formulierungen nutzen, um Vertrauen aufzubauen.
Technische Fachbegriffe einbauen: Bei spezialisierten Themen fachliches Know-how gezielt bei zum Ausdruck bringen.
Textfluss optimieren: Einen reibungslosen, fehlerfreien Lesefluss sicherstellen.
Quellenangaben: Aussagen mit zuverlässigen Quellen belegen, um die Glaubwürdigkeit zu steigern.
Zitate integrieren: Expertenzitate einbauen, um Autorität und Tiefe zu vermitteln und zu beweisen.
Statistiken einfügen: Argumente durch konkrete, quantitative Daten untermauern.
Besonders effektiv erwiesen sich Maßnahmen, die sowohl die Informationsdichte steigerten als auch die inhaltliche Glaubwürdigkeit stärkten:
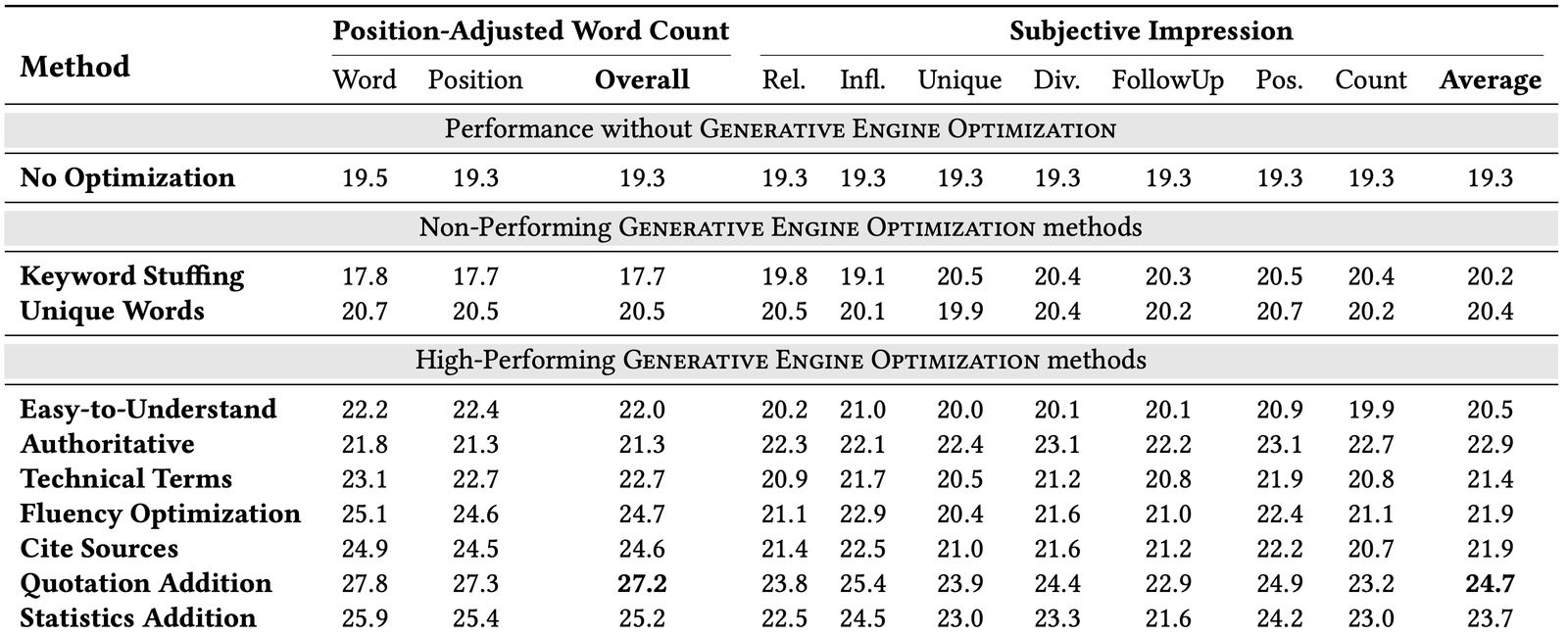
„Specifically, our top-performing methods, Cite Sources, Quotation Addition, and Statistics Addition, achieved a relative improvement of 30–40% on the Position-Adjusted Word Count metric and 15–30% on the Subjective Impression metric. These methods require minimal changes but significantly improve visibility in GE responses, enhancing both credibility and richness of content.“ (Aggarwal, et al. 2024)
Abbildung 1: Absolute Eindrucksmetriken der GEO-Methoden auf GEO-bench zeigen, dass traditionelle Ansätze wie Keyword Stuffing schwach abschneiden, während Methoden wie Statistics Addition und Quotation Addition bessere Ergebnisse erzielen. Die besten Methoden erreichen dabei Verbesserungen von bis zu 41 % bei der Position-Adjusted Word Count und 28 % bei der Subjective Impression.
Diese Ergebnisse bestätigen: Schon kleine Ergänzungen – etwa belastbare Daten, Zitate oder Quellen können die Sichtbarkeit spürbar steigern. Bemerkenswert ist außerdem, dass selbst stilistische Verbesserungen – etwa ein optimierter Textfluss und eine vereinfachte Sprache – die Sichtbarkeit um weitere 15–30 % steigern konnten. Das zeigt deutlich: Generative Engines bewerten nicht nur, was kommuniziert wird, sondern auch wie es präsentiert wird (Aggarwal, et al. 2024). Wer diese Maßnahmen konsequent anwendet und seine Inhalte regelmäßig aktualisiert – z. B. durch die Ergänzung neuer Studien, Statistiken oder Experteneinschätzungen – kann seine digitale Relevanz langfristig sichern und ausbauen.
Welche Herausforderungen existieren bei GEO?
Trotz der wachsenden Relevanz von GEO bringt die Optimierung von Inhalten für KI-generierte Suchergebnisse auch spezifische Herausforderungen mit sich. Ein zentrales Problem ist die eingeschränkte Steuerbarkeit: Generative Engines sind meistens proprietäre Systeme mit intransparenten Algorithmen. Inhalte werden nicht mehr über klare Ranking-Faktoren gelistet, sondern durch komplexe Modelle zusammengefasst und teils nur auszugsweise zitiert. Wann und wie eine Quelle erscheint, ist für Content-Ersteller kaum nachvollziehbar.
Hinzu kommt, dass die Aufmerksamkeit der Nutzer zunehmend auf die generierte Darstellung fokussiert bleibt, ohne die Quellen aufzurufen. Für viele Websites bedeutet dies einen potenziell sinkenden Traffic trotz hochwertiger Inhalte. Zudem entwickeln sich generative Modelle und das Suchverhalten rasant weiter. GEO-Strategien müssen sich diesem Wandel laufend anpassen, ähnlich wie sich SEO über die Jahre stetig verändert hat.
Auch die Erfolgsmessung ist komplexer geworden. Neue GEO-Metriken wie Sichtbarkeit nach Wortanzahl und Position oder ein subjektiver Eindruck sind zwar vielversprechend, aber deutlich weniger etabliert als klassische SEO-Kennzahlen.
Fazit
GEO markiert die nächste Evolutionsstufe der digitalen Sichtbarkeit – angepasst an eine Welt, in der KI-gesteuerte Suchsysteme wie ChatGPT, Perplexity und Gemini zunehmend klassische Suchmaschinen ergänzen oder sogar vollständig ablösen. Während SEO weiterhin relevant bleibt, reicht es künftig nicht mehr aus, Inhalte nur für traditionelle SERPs zu optimieren: GEO wird zur einer notwendigen Ergänzung.
Im Zentrum steht nicht nur das Was, sondern zunehmend das Wie der Informationsvermittlung. Erfolgreiche GEO-Strategien setzen auf eine Kombination aus aktueller Datenbasis, klarer Struktur, präziser Sprache und der gezielten Anreicherung von Inhalten durch verlässliche Quellen, Statistiken und Expertenzitate. Analysen zeigen, dass bereits kleine Anpassungen wie die Integration belastbarer Daten und stilistische Optimierungen die Sichtbarkeit in generativen KI-Antworten um bis zu 40 % steigern können (Aggarwal et al. 2024).
Gleichzeitig bleibt GEO ein dynamisches und noch wenig standardisiertes Feld. Intransparente Algorithmen, verändertes Nutzerverhalten und neue Metriken erschweren die gezielte Steuerung und Erfolgsmessung. Content-Ersteller bewegen sich damit in einem Umfeld, das sowohl Chancen als auch strategische Unsicherheiten mit sich bringt und eine kontinuierliche Anpassung erfordert.
Die Entwicklung von SEO hin zu GEO spiegelt eine umfangreiche Transformation des digitalen Marketings wider: Informationen müssen heute nicht nur gefunden, sondern in KI-generierten Antworten prominent und glaubwürdig platziert werden. Wer frühzeitig die richtigen Weichen stellt und seine Inhalte konsequent auf generative KI ausrichtet, bleibt auch in der KI-dominierten Zukunft auffindbar – und digital erfolgreich positioniert.
Quellenverzeichnis
Aggarwal, P., Murahari, V., Rajpurohit, T., Kalyan, A., Narasimhan, K., & Choudhury, M.: (2024): GEO: Generative engine optimization. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Online verfügbar unter: https://dl.acm.org/doi/abs/10.1145/3637528.3671900 [Zugriff am 13.05.2025].
Unsere Bewertung von Docling, Unstructured und LlamaParse zeigt Docling als die überlegene Lösung für die Extraktion strukturierter Daten aus unstrukturierten Nachhaltigkeitsberichten im PDF-Format, mit 97,9% Genauigkeit bei der Extraktion komplexer Tabellen und hervorragender Genauigkeit. Während LlamaParse eine beeindruckende Verarbeitungsgeschwindigkeit bietet (konstant etwa 6 Sekunden unabhängig von der Dokumentgröße) und Unstructured starke OCR-Fähigkeiten aufweist (100% Genauigkeit bei einfachen Tabellen, aber nur 75% bei komplexen Strukturen), sticht Docling aufgrund seiner ausgewogenen Performance für die Verarbeitung von Daten zur Analyse von Nachhaltigkeitsberichten heraus.
Zentrale Erkenntnisse:
Docling: Beste Gesamtgenauigkeit und Strukturerhaltung (97,9% Genauigkeit bei Tabellenzellen)
LlamaParse: Schnellste Verarbeitung (6 Sekunden pro Dokument unabhängig von der Größe)
Unstructured: Starke OCR-Leistung, aber langsamste Verarbeitung (51-141 Sekunden je nach Seitenzahl)
Dokumentenanalyse effizient gestalten?
Kontaktieren Sie uns für eine maßgeschneiderte Strategie zur Dokumentenanalyse.
Die manuelle Erhebung, Strukturierung, Bewertung und Validierung von Nachhaltigkeitsparametern stellt viele Unternehmen vor große Herausforderungen. Gleichzeitig bieten technologische Fortschritte, insbesondere in der Künstlichen Intelligenz, viele Möglichkeiten genau diese Herausforderungen zu adressieren und es drängt sich deshalb die Frage auf: Wie können unstrukturierte Nachhaltigkeitsberichte effizient in strukturierte, maschinenlesbare Daten für Analysen und Weiterverarbeitung umgewandelt werden? Als Spezialisten an der Schnittstelle von Nachhaltigkeit und digitaler Transformation wissen wir bei Procycons: Präzise Datenextraktion ist der Schlüssel für fundierte ESG-Analysen, automatisierte Berichterstattung und die Entwicklung wirksamer Klimastrategien.
PDF-Dokumente bleiben das Standardformat für Nachhaltigkeitsberichte, aber ihre unstrukturierte Natur schafft eine erhebliche Hürde für die Automatisierung. Die Extraktion strukturierter Informationen – von komplexen, quantitativen Emissionstabellen bis hin zu qualitativen Maßmahmenbeschreibungen zur Dekarbonisierung – erfordert ausgereifte Verarbeitungslösungen, die sowohl Inhaltsgenauigkeit als auch strukturelle Integrität gewährleisten können.
In dieser Studie vergleichen wir drei führenden Lösungen zur Verarbeitung von PDFs: Docling, Unstructured und LlamaParse. Unser Ziel ist es, herauszufinden, welche Lösung den Herausforderungen der Verarbeitung von Nachhaltigkeitsdokumenten am besten gerecht wird:
Erhaltung der Genauigkeit kritischer numerischer ESG-Daten
Beibehaltung der hierarchischen Struktur vorgegebener Nachhaltigkeitserklärungen
Korrekte Extraktion komplexer mehrstufiger Tabellen mit Emissionen, Ressourcennutzung und anderen Kennzahlen
Skalierbarkeit der Lösung auf größere Datenmengen von Unternehmen
Diese Bewertung bildet eine entscheidende Komponente unserer Arbeit bei Procycons, wo wir RAG (Retrieval-Augmented Generation)-Systeme und Wissensgraphen entwickeln, die die Nachhaltigkeitsberichterstattung von einem manuellen Prozess in einen automatisierten, KI-unterstützten Arbeitsablauf verändern. Durch die Optimierung der Grundlage der Dokumentenverarbeitung ermöglichen wir genauere nachgelagerte Anwendungen für Nachhaltigkeits-Benchmarking, automatisierte ESG-Berichterstattung und Entwicklung von Klimastrategien.
2. Überblick der wichtigsten Softwares zur PDF-Datenextraktion
2.1. Docling
Docling ist eine Open-Source-Lösung, die von DS4SD (IBM Research) entwickelt wurde, um die Extraktion und Transformation von Text, Tabellen und Strukturelementen aus PDFs zu erleichtern. Das Tool nutzt fortschrittliche KI-Modelle, darunter DocLayNet für Layoutanalyse und TableFormer für die Erkennung von Tabellenstrukturen. Docling wird weithin in KI-gestützter Dokumentenanalyse, Unternehmensdatenverarbeitung und Forschungsanwendungen eingesetzt und ist darauf ausgelegt, effizient auf lokaler Hardware zu laufen, während es Integrationen mit generativen KI-Ökosystemen unterstützt.
2.2. Unstructured
Unstructured ist eine Dokumentenverarbeitungsplattform, die entwickelt wurde, um komplexe Unternehmensdaten aus verschiedenen Formaten, einschließlich PDFs, DOCX und HTML, zu extrahieren und zu transformieren. Das Tool wendet OCR und Transformer-basierte NLP-Modelle für Text- und Tabellenextraktion an. Als sowohl Open-Source- als auch API-basierte Lösung wird Unstructured häufig für KI-gestütztes Content Enrichment, der juristischer Dokumentenanalyse und Automatisierung von Datenverarbeitungsprozessen eingesetzt und wird aktiv von Unstructured.io gepflegt, einem Unternehmen, das sich auf KI-Lösungen für Unternehmen spezialisiert hat.
2.3. LlamaParse
LlamaParse ist eine NLP-basierte Lösung des Unternehmens LlamaIndex, welche für die Extraktion strukturierter Daten aus Dokumenten, insbesondere PDFs, konzipiert ist. Das Tool integriert Llama-basierte NLP-Verarbeitungsketten für Textanalyse und Strukturerkennung. Während es bei einfachen Dokumenten gute Leistungen erbringt, hat es Schwierigkeiten mit komplexen Layouts, was es eher für wenig aufwendige Anwendungen wie Forschung und kleinere Dokumentenverarbeitungsaufgaben geeignet macht.
3. Methodik und Bewertungskriterien
Um eine faire und umfassende Bewertung der PDF-Verarbeitung für die Extraktion von Nachhaltigkeitsberichten durchzuführen, haben wir folgende Schlüsselmetriken analysiert:
Textextraktionsgenauigkeit: Stellt sicher, dass extrahierter Text korrekt und richtig formatiert ist, da Fehler die nachgelagerte Datenintegrität beeinflussen.
Tabellenerkennung und -extraktion: Entscheidend für Nachhaltigkeitsberichte mit tabellarischen Daten, bewertet die korrekte Identifizierung und Extraktion von Tabellen.
Abschnittsstrukturgenauigkeit: Bewertet die Beibehaltung der Dokumenthierarchie für Lesbarkeit und Benutzerfreundlichkeit.
Inhaltsverzeichnisgenauigkeit: Misst die Fähigkeit, ein Inhaltsverzeichnis für verbesserte Navigation zu rekonstruieren.
Verarbeitungsgeschwindigkeitsvergleich: Bewertet die Zeit, die für die Verarbeitung von PDFs unterschiedlicher Länge benötigt wird, und liefert Einblicke in Effizienz und Skalierbarkeit.
Wie gut funktionieren diese Extraktions-Tools mit Ihren eigenen Dokumenten?
Fordern Sie jetzt einen individualisierten Vergleichstest mit Ihren spezifischen Unternehmensunterlagen an.
Diese Berichte wurden aufgrund ihrer Vielfalt in Layout, Textstilen und Tabellenstrukturen ausgewählt. Um einen fairen Vergleich zu gewährleisten, haben wir die Berichte bei Bedarf gekürzt (z.B. Auswahl bestimmter Seitenbereiche für Pfizer, Takeda und UPS), um verschiedene Arten von Tabellen (einfach, mehrzeilig, Zellen mit Zusammenführungen) und Textinhalten (einspaltig, mehrspaltig, wortreiche Absätze, Aufzählungspunkte) einzubeziehen. Diese Auswahl ermöglichte es uns, zu untersuchen, wie jede Lösung mit unterschiedlichen Dokumentkomplexitäten umgeht, von präsentationsartigen Folien (DHL) bis hin zu umfangreichen Unternehmensberichten (Bayer) und gescannten Auszügen (UPS). Die Einbeziehung verschiedener Themen stellt die Relevanz für mehrere Branchen sicher, während die Bandbreite der Wortzahlen (~4.500 bis ~34.000) und Tabellenzahlen (3 bis 32) die Skalierbarkeit und Genauigkeit über Dokumentgrößen hinweg testet.
5. Ergebnisse und Diskussion
5.1. Übersichtstabelle der Metriken
Diese Vergleichstabelle hebt die wichtigsten Leistungsmetriken aller Lösungen hervor und unterstützt bei der Auswahl für die individuellen Anwendungsfälle der Nutzer.
Leistungsvergleichstabelle
Metrik
Docling
Unstructured
LlamaParser
Textextraktionsgenauigkeit
Hohe Genauigkeit, behält Formatierung bei
Effizient, inkonsistente Zeilenumbrüche
Probleme mit Mehrspalten, Wortzusammenführung
Tabellenerkennung & -extraktion
Erkennt komplexe Tabellen gut
OCR-basiert, variabel bei mehrzeiligen Tabellen
Gut bei einfachen, schlecht bei komplexen Tabellen
Abschnittsstrukturgenauigkeit
Klare hierarchische Struktur
Größtenteils genau, einige Fehlklassifizierungen
Probleme bei der Abschnittsunterscheidung
Inhaltsverzeichniserstellung
Genau mit korrekten Verweisen
Teilweise, einige Ungenauigkeiten
Kann nicht effektiv rekonstruieren
Leistungsmetriken
Moderat (6,28s für 1 Seite, 65,12s für 50 Seiten)
Langsam (51,06s für 1 Seite, 141,02s für 50 Seiten)
Schnell (6s unabhängig von der Seitenzahl)
5.2. Technologie hinter jeder Lösung
Die folgende Tabelle beschreibt die spezifischen Modelle und Technologien, die die Fähigkeiten der entsprechenden Lösung unterstützen.
Technologievergleichstabelle
Metrik
Docling
Unstructured
LlamaParser
Textextraktion
DocLayNet
OCR + Transformer-basiertes NLP
Llama-basierte NLP-Verarbeitungskette
Tabellenerkennung
TableFormer
Vision Transformer + OCR
Llama-basierter Tabellenparser
Abschnittsstruktur
DocLayNet + NLP-Klassifikatoren
Transformer-basierter Klassifikator
Llama-basierte Textstrukturierung
Inhaltsverzeichniserstellung
Layout-basiertes Parsing + NLP
OCR + Heuristisches Parsing
Llama-basierte Inhaltsverzeichniserkennung
5.3. Detaillierte Analyse
Nachfolgend vergleichen wir die Ausgaben jeder Lösung anhand von Auszügen aus verschiedenen Berichten, mit Fokus auf Text, Tabellen, Abschnitte und Inhaltsverzeichnisse.
5.3.1. Textextraktion
Der Originaltext aus dem „Takeda 2023“-PDF besteht aus zwei wortreichen Absätzen mit Fachbegriffen und klaren Absatzumbrüchen, die den Inhalt trennen.
Ergebnisse des Textextraktionsprozesses der 3 Tools
Erkenntnisse über den Prozess der Textextraktion
Docling:
Textgenauigkeit: Erreicht 100% Genauigkeit für den textlichen Inhalt, stimmt mit allen Sätzen einschließlich Titel und beiden Absätzen überein.
Vollständigkeit: Erfasst den gesamten Originaltext und behält Absatzumbrüche und Struktur bei.
Textmodifikationen: Behält die Originalformulierung und Fachbegriffe ohne Veränderung bei.
Formatierungserhaltung: Bewahrt Absatzumbrüche, die für die Lesbarkeit entscheidend sind, und trennt den Titel entsprechend des ursprünglichen Überschriftenstils.
LlamaParse:
Textgenauigkeit: Erreicht hohe Genauigkeit für Originalabsätze, enthält aber zusätzliche Inhalte, die im Quelltext nicht vorhanden sind.
Vollständigkeit: Fügt detaillierte technische Informationen hinzu, die nicht Teil des Beispielabschnitts sind, während der ursprüngliche Absatzumbruch verloren geht.
Textmodifikationen: Führt neue Sätze und Daten ein, was auf Überextraktion oder Halluzination hindeutet.
Formatierungserhaltung: Vereint Inhalte zu einem durchgehenden Block, was die Lesbarkeit verringert, obwohl die Titeltrennung beibehalten wird.
Unstructured:
Textgenauigkeit: Extrahiert Titel und Absätze korrekt, enthält aber erhebliche zusätzliche Inhalte, die im Originalabschnitt nicht vorhanden sind.
Vollständigkeit: Fügt erhebliche zusätzliche technische Details hinzu, die wahrscheinlich aus anderen Teilen des Dokuments stammen.
Textmodifikationen: Führt neue technische Informationen ein, ohne Fehler im Originalinhalt, verändert aber den Umfang der Ausgabe.
Formatierungserhaltung: Fasst alle inhakte in einem Blockzusammen, übersieht Absatzumbrüche und den strukturellen Aufbau des Texts trotz korrekter Titelformatierung.
5.3.2. Tabellenextraktionsleistung
Wir haben eine Tabelle aus dem „Bayer-Nachhaltigkeitsbericht-2023“ ausgewählt, um die Tabellenextraktionsleistung dieser Plattformen zu analysieren – siehe Abbildung unten.
Die Tabelle bietet eine Aufschlüsselung der Mitarbeiter nach Geschlecht (Frauen und Männer), Region (Gesamt, Europa/Naher Osten/Afrika, Nordamerika, Asien/Pazifik, Lateinamerika) und Altersgruppe (< 20, 20-29, 30-39, 40-49, 50-59, ≥ 60). Die Struktur ist hierarchisch:
Zweite Ebene: Regionen unter jedem Geschlecht (z.B. Frauen in Europa/Naher Osten/Afrika: 18.981).
Dritte Ebene: Altersgruppen unter jeder Region (z.B. Frauen in Europa/Naher Osten/Afrika, < 20: 6).
Ergebnisse des Tabellenexktrationsprozesses der 3 Tools
Erkenntnisse zur Datengenauigkeit
Docling:
Problem: Verpasst einen Datenpunkt („5“ für Männer in Lateinamerika, < 20) von 48 Einträgen, erreicht 97,9% Genauigkeit.
Auswirkung: Der Fehler ist isoliert und beeinflusst die Gesamtsummen nicht, beeinträchtigt jedoch die Vollständigkeit der Altersgruppe.
Stärke: Alle anderen Daten, einschließlich Geschlechtergesamtsummen, sind korrekt platziert.
LlamaParse:
Problem: Platziert Werte der Spalte „Gesamt“ falsch, verwendet Lateinamerika-Gesamtsummen anstelle von Geschlechtergesamtsummen.
Auswirkung: Systematische Spaltenverschiebung beeinträchtigt die gesamte Tabelleninterpretation, mit 100% Datenextraktion, aber 0% korrekter Platzierung.
Stärke: Erfasst den Datenpunkt „5“, den Docling verpasst.
Unstructured:
Problem: Schwerwiegender Spaltenverschiebungsfehler mit fehlenden Daten für Europa/Naher Osten/Afrika und verschobenen Regionen.
Auswirkung: Tabelle wird uninterpretierbar mit 75% Zellengenauigkeit (36/48 Einträge) und 0% Genauigkeit für Lateinamerika-Daten.
Stärke: Einige numerische Daten können manuell den korrekten Regionen zugeordnet werden.
Strukturintegrität
Docling:
Bewahrt die ursprüngliche Spaltenreihenfolge und hierarchische Verschachtelung, erhält dabei den strukturellen Aufbau des Texts.
Behandelt leere „Gesamt“-Spalte für Altersgruppen korrekt.
LlamaParse:
Kehrt die Spaltenreihenfolge mit falscher „Gesamt“-Platzierung um, verzerrt die Tabellenbedeutung.
Mangel an hierarchischen Verschachtelungsindikatoren, sekundär zu Spaltenfehlern.
Unstructured:
Leidet unter schweren Spaltenverschiebungen, wodurch die regionale Hierarchie bedeutungslos wird.
Behält teilweise die Trennung von Geschlecht und Altersgruppen bei, fehlt aber an klaren Verschachtelungsindikatoren.
Lässt „Gesamt“-Spalte für Altersgruppen korrekt leer, obwohl irrelevant angesichts der Datenfehlanpassung.
5.3.3. Abschnittsstruktur
Das Abschnittsbeispiel aus dem „UPS 2023“-PDF zeigt, wie die verschiedenen Lösungen mit hierarchischen Dokumentstrukturen umgehen, ein entscheidender Aspekt für die Beibehaltung der Dokumentorganisation. Das Beispiel enthält eine Hauptüberschrift gefolgt von einer Unterüberschrift, mit einer klaren hierarchischen Beziehung, die durch Formatierungsunterschiede im Originaldokument angezeigt wird.
Erkenntnisse zur Verarbeitung der Abschnittsstruktur
Docling:
Hierarchiedarstellung: Verwendet die gleiche Markdown-Ebene (##) für beide Überschriften, verfehlt die hierarchische Beziehung.
Textgenauigkeit: Erfasst den exakten Text beider Überschriften, einschließlich Groß-/Kleinschreibung und Zeichensetzung.
Formatierungserhaltung: Behält ursprüngliche Textelemente bei, verliert aber Stilunterschiede, die Überschriftsebenen unterscheiden.
LlamaParse:
Hierarchiedarstellung: Verwendet identische Markdown-Ebene (#) für beide Überschriften, verpasst die Eltern-Kind-Struktur.
Textgenauigkeit: Erfasst den Text beider Überschriften perfekt, bewahrt alle Textelemente.
Formatierungserhaltung: Behält Groß-/Kleinschreibung und Zeichensetzung bei, kann aber PDF-spezifische Stilunterschiede nicht abbilden.
Unstructured:
Hierarchiedarstellung: Verwendet korrekt unterschiedliche Markdown-Ebenen (# für Hauptüberschrift, ## für Unterüberschrift), spiegelt die hierarchische Beziehung richtig wider.
Textgenauigkeit: Erfasst den Text beider Überschriften mit allen Originalelementen.
Formatierungserhaltung: Kann PDF-Format nicht wiedergeben, kompensiert aber mit angemessener Markdown-Hierarchie, übertrifft andere Lösungen in struktureller Integrität.
5.3.4. Inhaltsverzeichnis
Das Original-Inhaltsverzeichnis aus dem „UPS 2023“-PDF enthält eine „Inhalt“-Überschrift gefolgt von Abschnittseinträgen mit Seitenzahlen, in einem zweispaltigen Layout mit gepunkteten Linien als Trenner zwischen Titeln und Seitenzahlen.
Erkenntnisse zum Verarbeiten des Inhaltsverzeichnis
Docling:
Textgenauigkeit: Erfasst alle Inhalte mit 100% Genauigkeit, einschließlich Titel, Seitenzahlen und Zeichensetzung.
Strukturdarstellung: Verwendet eine Markdown-Tabelle mit zwei Spalten, behält die Trennung von Titeln und Seitenzahlen bei.
Formatierungserhaltung: Behält gepunktete Linien innerhalb von Tabellenzellen bei, markiert aber „Inhalt“ als Unterüberschrift (##) anstatt als Hauptüberschrift.
LlamaParse:
Textgenauigkeit: Erreicht 100% Genauigkeit für alle Textelemente, einschließlich Titel, Seitenzahlen und gepunktete Linien.
Strukturdarstellung: Implementiert ein Aufzählungslisten-Format mit Titeln und Seitenzahlen in derselben Zeile, bewahrt den logischen Fluss.
Formatierungserhaltung: Behält gepunktete Linien bei und markiert „Inhalt“ korrekt als Hauptüberschrift (#), entsprechend seiner Bedeutung.
Unstructured:
Textgenauigkeit: Stark mangelhaft, erfasst nur den „Inhalt“-Titel, während alle Einträge und Seitenzahlen fehlen.
Strukturdarstellung: Enthält eine leere Markdown-Tabelle, die weder die Originalstruktur noch den Inhalt wiedergibt.
Formatierungserhaltung: Markiert „Inhalt“ als Unterüberschrift (##) und bietet keine Inhaltserhaltung, was zu einem vollständigen Strukturverlust führt.
5.4. Vergleich der Verarbeitungsgeschwindigkeit
Einer der wichtigsten Faktoren bei der Bewertung eines PDF-Verarbeitungstools für die automatisierte Dokumentenextraktion ist die Verarbeitungsgeschwindigkeit – wie schnell ein Tool Inhalte aus einem Dokument extrahieren und strukturieren kann. Ein langsames Tool kann die Workflow-Effizienz erheblich beeinträchtigen, besonders bei der Verarbeitung großer Dokumentenmengen.
Um die Geschwindigkeit zu vergleichen, haben wir eine Reihe von Test-PDFs verwendet, die aus einer einzelnen extrahierten Seite erstellt wurden. Durch den Vergleich ihrer Fähigkeit, Dokumente zunehmender Länge zu verarbeiten, haben wir das beste Tool für die strukturierte Dokumentenextraktion im großen Maßstab identifiziert. Wir haben die durchschnittliche verstrichene Zeit für LlamaParse, Docling und Unstructured bei der Verarbeitung von PDFs mit zunehmender Seitenzahl gemessen. Die Ergebnisse zeigen signifikante Unterschiede darin, wie jedes Tool mit Skalierbarkeit und Leistung umgeht – siehe Abbildung unten.
Vergleich der Vererbarbeitungsgeschwindigkeit der 3 Tools
Erkenntnisse zum Vergleich der Verarbeitungsgeschwindigkeiten
LlamaParse ist am schnellsten
LlamaParse verarbeitet Dokumente konstant in etwa 6 Sekunden, selbst wenn die Seitenzahl zunimmt.
Dies deutet darauf hin, dass es effizient mit der Dokumentenskalierung umgeht, ohne signifikante Verlangsamungen.
Docling skaliert linear mit zunehmenden Seiten
Die Verarbeitung von 1 Seite dauert 6,28 Sekunden, aber 50 Seiten dauern 65,12 Sekunden – eine nahezu lineare Zunahme der Verarbeitungszeit.
Dies zeigt, dass die Leistung von Docling stabil ist, aber proportional zur Dokumentgröße skaliert.
Unstructured hat Geschwindigkeitsprobleme
Unstructured ist deutlich langsamer und benötigt 51 Sekunden für eine einzelne Seite und über 140 Sekunden für große Dateien.
Es zeigt eine inkonsistente Skalierung, da 15 Seiten etwas weniger Zeit benötigen als 5 Seiten, wahrscheinlich aufgrund von Caching oder internen Optimierungen.
Obwohl seine Genauigkeit in einigen Bereichen höher sein mag, macht seine Geschwindigkeit es weniger praktisch für die Verarbeitung großer Datenmengen.
5.5. Analyseergebnisse
Die Ausgaben und Metriken zeigen deutliche Stärken und Schwächen der verschiedenen Lösungen, die nachfolgend analysiert werden:
Textextraktionsgenauigkeit:
Docling: Zeigt hohe Genauigkeit mit 100%iger Textübereinstimmung in wortverdichteten Absätzen (z.B. Takeda 2023), behält die ursprüngliche Formulierung, Fachbegriffe und Absatzumbrüche bei. Diese Konsistenz macht es zuverlässig für die Beibehaltung der Datenintegrität in Dokumenten mit umfangreichem textlichen Inhalt.
Unstructured: Bietet effiziente Textextraktion mit hoher Genauigkeit für Kerninhalte, führt aber Inkonsistenzen ein, wie das Zusammenführen von Absatzumbrüchen und das Hinzufügen von zusätzlichen Details. Diese Überextraktion deutet auf potenzielle Übergriffe aus anderen Dokumentabschnitten hin, was die Präzision beeinträchtigt.
LlamaParse: Hat Schwierigkeiten mit mehrspaltigen Layouts und Wortzusammenführungen, erreicht hohe Genauigkeit nur für einfachen Text, fügt aber irrelevante Inhalte hinzu. Dies weist auf eine Einschränkung im Umgang mit komplexen Textstrukturen hin, was seine Eignung für verschiedene Dokumentformate reduziert.
Tabellenerkennung & -extraktion:
Docling: Überzeugt bei der Erkennung komplexer Tabellen, bewahrt hierarchische Verschachtelung und Spaltenreihenfolge (z.B. komplizierte Tabelle aus Bayer 2023), mit einer einzelnen Ausnahme („5“ für Männer in Lateinamerika, < 20), was zu 97,9% Zellengenauigkeit führt. Die Verwendung von TableFormer gewährleistet eine robuste Strukturerhaltung, ideal für detaillierte tabellarische Daten.
Unstructured: Leistung ist variabel, mit OCR-basierter Extraktion, die numerisch erfolgreich ist (z.B. 100% Genauigkeit bei einfachen Tabellen), aber strukturell bei mehrreihigen Tabellen versagt (z.B. fehlende Daten durch Spaltenverschiebungen in Bayer 2023). Dies schränkt die Zuverlässigkeit für komplexe Layouts ein.
LlamaParse: Behandelt einfache Tabellen gut (z.B. 100% numerische Genauigkeit bei einfachen Tabellen), scheitert aber bei komplexen Tabellen, platziert „Gesamt“-Spalten falsch (z.B. Bayer 2023). Leistung sinkt erheblich bei komplexen Strukturen, was seinen Anwendungsbereich einschränkt.
Abschnittsstrukturgenauigkeit:
Docling: Behält klare hierarchische Struktur bei, verwendet aber einheitliche Markdown-Ebenen (##), verpasst Verschachtelungshinweise (z.B. UPS 2023 Abschnitt). Dieser kleine Mangel wird durch perfekte Textgenauigkeit ausgeglichen, was es trotz Formatierungseinschränkungen effektiv für die Lesbarkeit macht.
Unstructured: Größtenteils genau, mit korrekter Textextraktion (z.B. UPS 2023 Abschnitt), verwendet aber die gleiche Markdown-Ebene (#) für alle Überschriften, spiegelt Hierarchie nicht wider. Diese Gemeinsamkeit mit Docling und LlamaParse deutet auf eine gemeinsame Einschränkung bei der strukturellen Differenzierung hin.
LlamaParse: Schwierigkeiten bei der Abschnittsunterscheidung, verwendet einheitliche Ebenen (#) und mangelt an hierarchischer Klarheit (z.B. UPS 2023), ähnlich wie andere. Seine Textgenauigkeit ist hoch, aber strukturelle Schwächen reduzieren die Nutzbarkeit für organisierte Navigation.
Inhaltsverzeichnis (ToC) Erstellung:
Docling: Erreicht genaue Inhaltsverzeichnisrekonstruktion mit 100% Textgenaugkeit, verwendet ein Tabellenformat mit gepunkteten Linien, unterschätzt aber die Bedeutung von „Inhalt“ mit ##. Dies macht es trotz kleinerer Formatierungsprobleme sehr effektiv für die Navigation.
Unstructured: Versagt dramatisch, erfasst nur „Inhalt“ mit einer leeren Tabelle, verpasst alle Einträge und Seitenzahlen (z.B. UPS 2023 Inhaltsverzeichnis). Dies zeigt eine erhebliche Schwäche im Umgang mit zweispaltigen Layouts und gepunkteten Linientrennern.
LlamaParse: Kann nicht effektiv rekonstruieren, obwohl es eine Aufzählungsliste mit gepunkteten Linien und korrektem Text verwendet, ordnet „Inhalt“ mit # ein. Seine Unfähigkeit, die Struktur vollständig zu reproduzieren, begrenzt seinen Nutzen im Vergleich zu Docling.
Leistungsmetrik (Verarbeitungsgeschwindigkeit):
Docling: Bietet moderate Geschwindigkeit (6,28s für 1 Seite, 65,12s für 50 Seiten) mit linearer Skalierung, balanciert Genauigkeit und Effizienz. Dies macht es gut geeignet für Verarbeitung im Unternehmensmaßstab, wo vorhersehbare Leistung entscheidend ist.
Unstructured: Hat erhebliche Geschwindigkeitsprobleme (51,06s für 1 Seite, 141,02s für 50 Seiten), zeigt inkonsistente Skalierung. Diese Ineffizienz untergräbt seine ansonsten anständige Genauigkeit und macht es weniger praktisch für Workflows mit großen Datenmengen.
LlamaParse: Exzelliert in Geschwindigkeit (~6s konstant, selbst für 50 Seiten), zeigt bemerkenswerte Skalierbarkeit. Diese Effizienz positioniert es als starken Kandidaten für schnelle Verarbeitung, obwohl seine Genauigkeitseinbußen seine Verwendung auf einfachere Dokumente beschränken.
6. Fazit
Basierend auf unseren Benchmark-Ergebnissen, einschließlich der Erkenntnisse zur Verarbeitungsgeschwindigkeit, erweist sich Docling als die robusteste Lösung für die Verarbeitung komplexer Geschäftsdokumente. Es bietet hohe Textextraktionsgenauigkeit, überlegene Tabellenstrukturerhaltung und effektive Inhaltsverzeichnisrekonstruktion, unterstützt durch moderate und vorhersehbare Verarbeitungsgeschwindigkeiten (z.B. 6,28s für 1 Seite, linear skalierend auf 65,12s für 50 Seiten). Der Einsatz fortschrittlicher Modelle wie DocLayNet und TableFormer gewährleistet die zuverlässige Verarbeitung verschiedener Dokumentelemente, mit nur geringfügigen Ausnahmen (z.B. „5“ in der Bayer-Tabelle). Diese Balance aus Präzision, struktureller Integrität und effizienter Leistung macht Docling zur empfohlenen Wahl für Anwendungen, die Skalierbarkeit und Genauigkeit erfordern, wie Unternehmensdatenverarbeitung und Business Intelligence.
Unstructured funktioniert gut bei der Extraktion von Text und einfachen Tabellen und erreicht in simplen Anwendungsfällen eine numerische Genauigkeit von 100%, aber Inkonsistenzen wie Spaltenverschiebungen in komplexen Tabellen und unvollständige Inhaltsverzeichniserstellung schränken die Zuverlässigkeit ein. Die deutlich langsamere Geschwindigkeit (z.B. 51,06s für 1 Seite, 141,02s für 50 Seiten) beeinträchtigt zusätzlich die Praktikabilität, was darauf hindeutet, dass Unstructured am besten für weniger komplexe Dokumente oder Szenarien geeignet ist, in denen Geschwindigkeit und Ressourcenbeschränkungen nicht entscheidend sind. Eine Verbesserung der Geschwindigkeitsineffizienzen und des strukturellen Parsings könnte die Wettbewerbsfähigkeit steigern.
LlamaParse zeichnet sich durch die außergewöhnliche Verarbeitungsgeschwindigkeit aus (~6s konstant über alle Seitenzahlen), bietet die höchste Effizienz und Skalierbarkeit. Das Tool funktioniert angemessen für grundlegende Extraktionen, mit starker numerischer Genauigkeit bei einfachen Tabellen und Texten, hat aber Schwierigkeiten mit komplexer Formatierung (z.B. mehrspaltiger Text, komplizierte Tabellen) und Inhaltsverzeichnisrekonstruktion. Der Geschwindigkeitsvorteil macht es ideal für leichte, unkomplizierte Aufgaben, aber die strukturellen Schwächen und Einbußen bei der Genauigkeit machen es im Vergleich zu Docling weniger geeignet für umfassende Dokumentenverarbeitung.
Für Anwendungen, die Präzision, Effizienz und strukturelle Integrität priorisieren – entscheidend für Geschäftsanalysen – bleibt Docling die optimale Lösung. Die lineare Geschwindigkeitsskalierung stellt sicher, dass große Dokumente effektiv verarbeitet werden können, während LlamaParses zügige Verarbeitung eine Nische für schnelle, einfache Extraktionen bietet. Unstructured benötigt trotz des Potenzials erhebliche Optimierungen in Geschwindigkeit und Tabellenverarbeitung, um konkurrenzfähig zu sein. Zukünftige Verbesserungen für Unstructured könnten sich auf die Reduzierung der Verarbeitungszeiten und die Verbesserung der Tabellenanalyse konzentrieren, während LlamaParse von einer besseren Strukturerkennung profitieren könnte, um den Geschwindigkeitsvorteil in breiteren Anwendungen anzuwenden.
Nachhaltigkeit in der Logistik: Herausforderungen, Chancen und Lösungen
Der ständig steigende CO2-Ausstoß wirkt sich negativ auf das Weltklima aus – das ist nichts Neues. Die deutsche Logistikbranche hat mit einem Ausstoß von rund 20 Prozent aller Emissionen an Treibhausgasen einen wesentlichen Anteil daran und sieht sich daher mit verschiedenen Herausforderungen konfrontiert. Die Branche steckt in der Zwickmühle zwischen Reduzierung der Transportkosten und dem Druck, die Emissionen zu reduzieren, um die ständig strenger werdenden gesetzlichen Vorschriften einzuhalten. Es existieren mehrere Gesetzesvorschriften wie beispielsweise das Klimaschutzgesetz und im Schiffsverkehr die IMO-Verordnung, die die Schwefelemissionen von Schiffen begrenzt und die Preise für den Treibstoff für Schiffe und LKWs erhöht.
Doch mit der Umsetzung der Klimaneutralität geht es nicht so voran, wie es notwendig wäre. Ein wesentlicher Grund ist, dass viele Ansätze der Reduktion der Treibhausgase für die Unternehmen eine starke finanzielle Belastung darstellen. Fraglos die größte Herausforderung, vor der die Logistikbranche steht, liegt in der Nutzungsmöglichkeit nachhaltig produzierter Brennstoffe und einer Modernisierung der eigenen Fahrzeugflotte. Es ist mehr denn je notwendig, grüne Technologien in der Logistikbranche einzuführen, um damit die Nachhaltigkeit zu fördern. Gleichzeitig bietet sich dadurch die Chance, die Effizienz zu steigern sowie mittel- bis langfristig Kosten einzusparen. Dies erfordert jedoch innovative Lösungen und das Engagement der Unternehmen der gesamten Lieferkette.
Die nachhaltige Logistik befasst sich mit allen Prozessen rund um den Lebenszyklus von Produkten während der gesamten Wertschöpfungskette. Bereiche, die davon berührt sind, sind die Beschaffung, die Produktion sowie die Auslieferung und Entsorgung. Es geht aber nicht ausschließlich um die Zu- und Auslieferung von Waren, Rohstoffen und/oder Produktteilen. Auch die Gestaltung der darunterliegenden Fertigungs- und Auslieferungsprozesse sowie die Optimierung sowohl der Daten- als auch der Informationsflüsse gehört dazu. Die Bewegung der Ware über Straße, Schiene, Luft und Wasser muss dabei berücksichtigt werden, genauso wie die Prozesse, die der Lieferkette zugrunde liegen.
Die deutsche Logistikbranche, verantwortlich für rund 20 Prozent der Treibhausgasemissionen, steht vor der Herausforderung, durch innovative Lösungen und grüne Technologien die CO2-Emissionen zu reduzieren und Nachhaltigkeit zu fördern.
Was sind die Treiber und Ziele der Nachhaltigkeit in der Logistik?
Es steht fraglos fest, dass sich der Klimawandel in den nächsten Jahren weiter beschleunigen wird – mit verheerenden Folgen für Mensch und Natur. Darauf reagiert der Staat, indem er immer strengere Regeln und Gesetze aufstellt, die die Unternehmen der Branche zwingen, nachhaltiger zu agieren. Weiterhin machen es die Meinung der Kunden, der Druck der öffentlichen Meinung und die Veränderung am Markt nötig, gegen alle Widerstände nachhaltige Lieferketten aufzubauen. Dabei spielen auch mehr und mehr ethische Aspekte eine Rolle, sodass vor allem die Rückverfolgbarkeit der Lieferungen eine erhöhte Relevanz hat. In diesem Zusammenhang zählt das sogenannte „Lieferkettensorgfaltspflichtengesetz“ (kurz Lieferkettengesetz), das die unternehmerische Verantwortung bezüglich der Einhaltung von Menschenrechten innerhalb der globalen Lieferketten regelt.
Bis heute hält die Logistikbranche, die einem extrem hohen Wettbewerbsdruck ausgesetzt ist, nicht die gesetzlich vorgeschriebenen Begrenzungen der CO2-Emissionen ein. Die Ziele, die zu mehr Nachhaltigkeit in diesem Sektor führen sollen, sind breit aufgestellt. Um einen Einblick in die verschiedenen Vorteile zu bieten, sind einige hier beispielhaft aufgeführt:
Verringerung des CO2-Fußabdrucks für mehr Klimaschutz
Eine höhere Ressourceneffizienz beispielsweise durch Wiederverwendung
Eine erhöhte Rentabilität und viele Wettbewerbsvorteile
Erfüllung diverser gesetzlicher Standards und Abwendung von Strafen
Aufbau eines positiven Markenimages und einer höheren Kundenbindung
Um diese Ziele im Unternehmen effektiv umzusetzen, müssen alle Beteiligten des Logistiksektors wie Speditionen, Bahnbetreiber, Fluglinien und Schiffsspeditionen einschließlich ihrer vor- und nachgelagerten Lieferketten diesen Veränderungsprozess proaktiv angehen. Viele kompetente und innovative Beratungsunternehmen helfen zuverlässig, die eigene Ökobilanz zu optimieren.
Welche Methoden existieren, um die Nachhaltigkeit in der Logistik zu messen?
Für Unternehmen der Logistikbranche wird es immer wichtiger und für viele ist es ein echtes Anliegen, die eigenen CO₂-Emissionen zu reduzieren. Doch die erzielten Reduktionen vollständig messbar zu machen, ist – vor allem bei Betrachtung der gesamten Lieferkette – nicht einfach. Um die Emissionen, die ein Unternehmen ausstößt, messbar zu machen, müssen drei Dimensionen sichtbar gemacht werden. Dazu gehört
die Sichtbarmachung der gesamten Ausstoßmenge an klimaschädlichen Gasen des eigenen Unternehmens
die Messung der Emissionen der Energielieferanten
die Verfolgung der Emissionen der vor- und nachgelagerten Unternehmen der Lieferkette.
Unternehmen müssen im Vorfeld sinnvolle Key Performance Indicators (kurz: KPIs) definieren, um den Erfolg der Nachhaltigkeitsstrategie des eigenen Unternehmens tatsächlich messbar nachvollziehen zu können.
Um dies zu erreichen, existieren verschiedene Softwareprogramme von Spezialisten, die Unternehmen der Logistikbranche mit der Bereitstellung der Messwerte, die für die Bestimmung der KPIs notwendig sind. Eines der wichtigsten KPIs ist die relative Emissionsreduktion an Treibhausgasen. Für diesen Messwert ist die Bestimmung eines Bezugspunktes unbedingt erforderlich. Dieser Messwert wird in Prozent gemessen und soll helfen, festzulegen, ob ein CO2-Reduktionsziel erreicht wurde.
Wird eine solche Software im Unternehmen eingesetzt, können die Unternehmen, die ihren CO2-Fußabdruck verkleinern möchten, wertvolle Daten gewinnen, um ihre gesamte Lieferkette zu analysieren, zu überwachen und ggf. zu optimieren. In die Berechnungen fließen die KPIs aus den Sektoren Einkauf, Lagerhaltung, Lieferung, Logistik und Transport ein. Als Messkriterien gelten in den meisten Fällen die Zeit, die Kosten, die Produktivität und Servicequalität. Die Darstellung und Überwachung erfolgen in Echtzeit über spezielle Softwareprodukte.
Sowohl die Industrie 4.0 als auch die Logistik 4.0 – wo Softwareprodukte wertvolle Informationen und Auswertungen liefern, um belastbare Ergebnisse zu erhalten – ist es in Zeiten der fortschreitenden Digitalisierung sehr viel einfacher geworden, notwendige Daten für die Analyse zu sammeln. Daher ist eine Vernetzung der speziellen Softwareprodukte verschiedener Abteilungen, beispielsweise ein Lagerverwaltungssystem, absolut notwendig, um an diese Daten zu kommen. Auch das firmeneigene ERP-System bietet wertvolles Datenmaterial, aus dem relevante Informationen und Daten herausgefiltert werden können.
Digitale Technologien wie CarbonPath ermöglichen es Logistikunternehmen, ihren CO₂-Fußabdruck zu erfassen, zu analysieren und effektiv zu reduzieren.
Welche innovative Technologien unterstützen die Nachhaltigkeit in der Logistik?
Durch den Einsatz digitaler Technologien können sämtliche Produkte und Prozesse in der Logistik ressourcenschonender und damit sozial verträglicher gestaltet werden. Es geht primär um die Vernetzung von Wertschöpfungsketten, um vorhandene Ressourcen und Produkte im Sinne der Kreislaufwirtschaft effektiv zu nutzen und damit den Nachhaltigkeitsgedanken zu stärken. Ein Beispielprodukt soll kurz genauer beleuchtet werden.
Ein innovatives Tool, das in der Logistikbranche für mehr Nachhaltigkeit eingesetzt werden kann, ist die Software CarbonPath. Diese Softwarelösung beinhaltet mehrere Funktionen und zielt konkret darauf ab, dass Logistikunternehmen ihren ökologischen Fußabdruck ganzheitlich erfassen, analysieren und messen. Ziel ist, alle Möglichkeiten der Reduzierung zu eruieren, andere Stakeholder mit ins Boot zu holen. Die gemessenen konkreten Werte bezüglich der Emissionen der Treibhausgase der Fahrzeugflotte können später für Dokumentationszwecke auf Knopfdruck als pdf-Dokument exportiert werden.
Welche Herausforderungen und Erfolgsfaktoren prägen nachhaltige Logistik?
Die moderne Logistikbranche sieht sich verschiedenen Herausforderungen gegenüber, die für die betreffenden Unternehmen schwer zu bewältigen sind. Primär sind es natürlich die zu hohen CO2-Emissionen, die reduziert werden müssen, um die Klimaziele zu erreichen. Ein ineffizientes Ressourcenmanagement, der akute Fachkräftemangel, eine fehlende Transparenz innerhalb der gesamten Lieferkette sowie eine zu geringe Digitalisierungsquote sind weitere Faktoren, die zu teils massiven Einschränkungen der Handlungsfreiheit der Unternehmen führen. Gerade in Deutschland – dem Land, das Bürokratie in neue Sphären hebt – wird noch viel zu viel papierbasiert gearbeitet
Wesentliche Erfolgsfaktoren für die Gestaltung und strategische Planung der Umsetzung sind die Automatisierung durch den Einsatz von innovativen Technologien. Automatisierung und Robotik helfen beispielsweise beim Einsatz von Lagersystemen und sorgen für Transparenz. Um die ständig größer werdenden Datenmassen effizient nutzen zu können, helfen Tools der Datenanalyse und die Künstliche Intelligenz. Diese kann eingesetzt werden, um die Fahrtrouten der gesamten Fahrzeugflotte zu optimieren. Telematiksysteme wiederum ermöglichen einerseits die Echtzeitüberwachung der Fahrzeuge, andererseits können sie unterstützen, Leerfahrten zu vermeiden. Die Implementierung eines ESG-Konzepts (wobei ESG für „Environment, Social, Governance“ steht) kann durch kontinuierliche KPI-Messung besser überwacht werden.